OCRopus - OCRopus
 | |
| Tuzuvchi (lar) | Tomas Breuel, DFKI |
|---|---|
| Dastlabki chiqarilish | 2007 yil 9 aprel[1] |
| Barqaror chiqish | 1.3.3 / 16 dekabr 2017 yil |
| Ombor | |
| Yozilgan | C ++ va Python |
| Operatsion tizim | FreeBSD, Linux, Mac OS X |
| Turi | Optik belgilarni aniqlash |
| Litsenziya | Apache litsenziyasi v2.0 |
| Veb-sayt | github |
OCRopus a ozod hujjatlarni tahlil qilish va optik belgilarni aniqlash (OCR) tizimi ostida chiqarilgan Apache litsenziyasi v2.0 yordamida juda modulli dizaynga ega buyruq qatori interfeyslari.
OCRopus Tomas Breuel boshchiligida ishlab chiqilgan Sun'iy aql bo'yicha nemis tadqiqot markazi yilda Kaiserslautern, Germaniya va homiysi bo'lgan Google.
Tavsif
OCRopus ayniqsa katta hajmda foydalanish uchun mo'ljallangan edi raqamlashtirish kabi kitoblarning loyihalari Google Books, Internet arxivi yoki kutubxonalar. Ko'p sonli til va shriftlarni qo'llab-quvvatlash kerak.[2] Shu bilan birga, u ish stoli va ofis dasturlari yoki ko'rish qobiliyati past odamlar uchun dastur uchun ham ishlatilishi mumkin.
OCRopusning asosiy tarkibiy qismlari quyidagilar:
Ushbu komponentlar uchun bitta yoki bir nechta skript mavjud. The modulli yondashuv individual ish oqimlaridan foydalanishga va individual qadamlarni almashtirishga imkon beradi.
Odatiy bo'lib, OCRopus inglizcha matnlar uchun model va matn uchun model bilan birga keladi Fraktur. Ushbu modellar skriptga ishora qiladi va asosan haqiqiy tilga bog'liq emas.[3] Yangi belgilar yoki til variantlari yangi yoki qo'shimcha ravishda o'qitilishi mumkin.
Yaqinda matnni aniqlashga asoslangan takrorlanadigan neyron tarmoqlari (LSTM ) va til modelini talab qilmaydi. Bu bir vaqtning o'zida ingliz, nemis va frantsuz tillarini yaxshi tan olish natijalari ko'rsatilgan tildan mustaqil modellarni tayyorlashga imkon beradi.[4] Ga qo'shimcha ravishda Lotin yozuvi, kabi boshqa skriptlar uchun natijalar mavjud Sanskritcha, Urdu, Devanagari va Yunoncha.
Tegishli trening orqali juda yaxshi aniqlash ko'rsatkichlariga erishish mumkin. Ushbu qo'shimcha harakatlar, bugungi kunda keng tarqalgan bo'lmagan, boshqa OCR dasturlarining diqqat markazida bo'lmagan qiyin hujjatlar yoki skriptlar uchun juda muhimdir.[5][6]
Tarix
2007 yil 9-aprelda OCRopus ilg'or OCR texnologiyalarini rivojlantirish bo'yicha Google homiyligidagi loyiha sifatida e'lon qilindi.[1] Moliyalashtirish uch yil muddatga berildi va xususan doktorlik dissertatsiyalari va postdoktorlik lavozimlarini qamrab oldi DFKI va Kayzerslautern universiteti. Buning evaziga OCRopus matnni avtomatik ravishda tanib olish uchun ham ishlatilgan Google Book Search.[7] Ochiq manbali litsenziya bo'yicha litsenziyalash boshidanoq sanoat va akademik tadqiqotlar o'rtasidagi hamkorlikni osonlashtirish uchun amalga oshirildi.[8] OCRopus kompaniyasidan qo'shimcha mablag 'olindi Endryu V. Mellon jamg'armasi va BMBF.[9]
Birinchi alfa-versiya 0.1 2007 yil 22-oktabrda chiqdi va 2007 yil dekabrdan 2009 yil maygacha bo'lgan bir nechta pre-relizlar, 2010 yil mart oyida 0.4.4 barqaror versiyasiga erishildi.[10] Dastlab, dasturiy ta'minot ishlab chiqilgan C ++, Python va Lua bilan Jam kabi tizimni yaratish. To'liq manba kodini qayta ishlash Python modullarida 0.5 versiyada (2012 yil iyun) bajarildi va chiqarildi.[11]
Dastlab, Tesserakt yagona matnni aniqlash moduli sifatida ishlatilgan. 2009 yildan beri (0.4 versiyasi) Tesseract faqat plagin sifatida qo'llab-quvvatlandi. Buning o'rniga o'z-o'zidan ishlab chiqilgan matnni taniydigan (shuningdek segmentga asoslangan) ishlatilgan.[12] Keyinchalik bu tanib oluvchidan OpenFST bilan birga foydalanilgan[13] uchun tilni modellashtirish tanib olish bosqichidan keyin. 2013 yildan boshlab qo'shimcha tan olish takrorlanadigan neyron tarmoqlari (LSTM ) taklif qilindi, bu 2014 yil noyabr oyida 1.0 versiyasining chiqarilishi bilan yagona taniqli hisoblanadi.[14][15]
Manba kodi boshqariladi GitHub va ishlab chiquvchilar jamoasi tomonidan qo'llab-quvvatlanadi va rivojlanadi.[16] OCRopusning amaldagi versiyasi 1.3.3 (2017 yil dekabr).[17]
Foydalanish
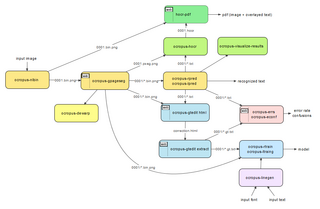
OCRopus buyruq satridan foydalanish mumkin. O'rnatilgandan so'ng, uni kirish rasmlarini ko'rsatish orqali chaqirish mumkin. U tanilgan matnni chiqaradi standart chiqish to'g'ridan-to'g'ri yoki uni shunday yozing HOCR (HTML -base) kodlarni fayllarga qo'shib, undan qidirish mumkin bo'lgan PDF formatiga o'tkazilishi mumkin. Agar aniqroq boshqarish zarur bo'lsa, buyruq satrida aniq operatsiyalarni bajarish uchun imkoniyatlar belgilanishi mumkin (masalan, bitta qatorni tanib olish).[18]
OCRopus qo'ng'iroqlari uchun rasmdagi matnni tanib olishga chaqiruvchi misol:
# binarizationocropus-nlbin testlarini bajaring / ersch.png -o kitob # sahifa tartibini amalga oshiring analyocropus-gpageseg book / 0001.bin.png # matn satrini tanib olishni (fraktur modeli bilan) ocropus-rpred -m modellari / fraktur.pyrnn.gz book / 0001 / *. bin.png # HTML outputocropus-hocr book / 0001.bin.png -o book / 0001.html yaratishBoshqa vositalar OCRopus-ning o'quv qismiga qaratilgan. Lotin, yunon, kirill va hind yozuvlaridan matn chiqarish uchun OCRopus modellari mavjud.[19]
Adabiyotlar
- ^ a b Breuel, Tomas (2007 yil 9 aprel). "OCRopus ochiq manbali OCR tizimini e'lon qilish". Google Developers Blog. Olingan 29 dekabr 2017.
- ^ Breuel, Tomas (2009). OCRopus OCR tizimidagi so'nggi yutuqlar. Ko'p tilli OCR bo'yicha xalqaro seminar materiallari. MOCR '09. Nyu-York, Nyu-York, AQSh: ACM. 2-bet: 1-22: 10. doi:10.1145/1577802.1577805. ISBN 9781605586984.
- ^ "Modellar". ocropy wiki. Olingan 5 yanvar 2018.
- ^ Ul-Hasan, Adnan; Breuel, Tomas M. (2013). LSTM tarmoqlari yordamida tildan mustaqil OCR qura olamizmi?. Ko'p tilli OCR bo'yicha 4-Xalqaro seminar materiallari. MOCR '13. Nyu-York, Nyu-York, AQSh: ACM. 9-bet: 1-9: 5. doi:10.1145/2505377.2505394. ISBN 9781450321143.
- ^ Springmann, Uve (2016 yil 1-dekabr). "OCR für alte Drucke". Informatik-Spektrum (nemis tilida). 39 (6): 459–462. doi:10.1007 / s00287-016-1004-3. ISSN 0170-6012.
- ^ Simistira, F.; Ul-Xasan, A .; Papavassiliou, V.; Gatos, B .; Katsuros, V .; Liwicki, M. (avgust 2015). LSTM tarmoqlaridan foydalangan holda tarixiy yunon politonik yozuvlarini tan olish. 2015 Hujjatlarni tahlil qilish va tan olish bo'yicha 13-Xalqaro konferentsiya (ICDAR). 766-770 betlar. doi:10.1109 / icdar.2015.7333865. ISBN 978-1-4799-1805-8.
- ^ "OCRopus tadqiqot loyihasi". www.dfki.de. Olingan 5 yanvar 2018.
- ^ Breuel, Tomas M. (2008 yil 28-yanvar). "OCRopus ochiq manbali OCR tizimi". Ishlar jildi 6815, Hujjatlarni tan olish va olish XV. Hujjatlarni tanib olish va olish XV. 6815: 68150F – 68150F – 15. Bibcode:2008 SPIE.6815E..0FB. CiteSeerX 10.1.1.99.8505. doi:10.1117/12.783598.
- ^ "ocropus loyihasi veb-sayti". Google Project Hosting. Yanvar 2019. Arxivlangan asl nusxasi 2012 yil 24 dekabrda.
- ^ "Eski versiyalar - okropiya". GitHub. Olingan 5 yanvar 2018.
- ^ "OCRopus 0.5". Google guruhlari. 2012 yil 2-iyun.
- ^ OCRopus hatto sukut bo'yicha Tesseract bilan bog'lanmaydi.
- ^ Rasmiy OpenFST veb-sayti.
- ^ "ocropy - v1.0 versiyasi". GitHub. 2014 yil 2-noyabr. Olingan 5 yanvar 2018.
- ^ Breuel, T. M .; Ul-Hasan, A .; Al-Azaviy, M. A .; Shafait, F. (2013 yil avgust). LSTM tarmoqlaridan foydalangan holda bosilgan ingliz va frakturalar uchun yuqori samarali OCR. 2013 Hujjatlarni tahlil qilish va tan olish bo'yicha 12-xalqaro konferentsiya. 683-687 betlar. doi:10.1109 / icdar.2013.140. ISBN 978-0-7695-4999-6.
- ^ "ocropy: hujjatlarni tahlil qilish va OCR uchun Python-ga asoslangan vositalar", GitHub, olingan 5 yanvar 2018
- ^ "Okropiyani chiqaradi". GitHub. Olingan 5 yanvar 2018.
- ^ "ocropy wiki". GitHub. Olingan 30 dekabr 2017.
- ^ "okropiya modellari". GitHub. Olingan 13 mart 2018.
Tashqi havolalar
- okropiya kuni GitHub
- GitHub-da Ocropy wiki
- IUPR nashr server (OCRopus-da ishlatiladigan ko'plab algoritmlarning orqasidagi hujjatlar)