Katta ma'lumotlar - Big data - Wikipedia
Bu maqola o'z ichiga olishi mumkin haddan tashqari ko'p iqtiboslar. (Noyabr 2019) (Ushbu shablon xabarini qanday va qachon olib tashlashni bilib oling) |

Katta ma'lumotlar bu axborotni tahlil qilish, muntazam ravishda chiqarib olish yoki boshqa usullar bilan ishlash usullarini ko'rib chiqadigan soha ma'lumotlar to'plamlari juda katta yoki murakkab bo'lib, an'anaviy tarzda ko'rib chiqilmaydi ma'lumotlarni qayta ishlash dasturiy ta'minot. Ko'p holatlar (satrlar) bo'lgan ma'lumotlar kattaroqdir statistik kuch, murakkabligi yuqori bo'lgan ma'lumotlar (ko'proq atributlar yoki ustunlar) yuqori darajaga olib kelishi mumkin noto'g'ri kashfiyot darajasi.[2] Ma'lumotlarning katta muammolariga quyidagilar kiradi ma'lumotlarni yozib olish, ma'lumotlarni saqlash, ma'lumotlarni tahlil qilish, qidirmoq, almashish, o'tkazish, vizualizatsiya, so'rov qilish, yangilanmoqda, axborotning maxfiyligi va ma'lumotlar manbai. Katta ma'lumotlar dastlab uchta asosiy tushunchalar bilan bog'liq edi: hajmi, xilma-xillikva tezlik. Katta ma'lumotlar bilan ishlashda biz namuna olmasligimiz mumkin, balki shunchaki nima bo'lishini kuzatish va kuzatib borishimiz mumkin. Shuning uchun katta ma'lumotlarga odatda an'anaviy dasturiy ta'minotni maqbul vaqt ichida qayta ishlash hajmidan kattaroq kattalikdagi ma'lumotlar kiradi qiymat.
Terminning amaldagi ishlatilishi katta ma'lumotlar ning ishlatilishiga murojaat qilishga moyil bashoratli tahlil, foydalanuvchi xatti-harakatlarini tahlil qilish, yoki chiqaradigan ba'zi boshqa zamonaviy ma'lumotlar tahlil usullari qiymat ma'lumotlardan va kamdan-kam hollarda ma'lumotlar to'plamining ma'lum hajmiga qadar. "Hozir mavjud bo'lgan ma'lumotlar miqdori haqiqatan ham katta ekanligiga shubha yo'q, ammo bu yangi ma'lumotlar ekotizimining eng muhim xususiyati emas."[3]Ma'lumotlar to'plamini tahlil qilish "biznes tendentsiyalarini aniqlash, kasalliklarning oldini olish, jinoyatchilikka qarshi kurashish va boshqalar" bilan yangi korrelyatsiyalarni topishi mumkin.[4] Olimlar, korxona rahbarlari, tibbiyot amaliyotchilari, reklama va hukumatlar bir qatorda doimiy ravishda, shu jumladan sohalardagi katta ma'lumotlar to'plamlari bilan bog'liq qiyinchiliklarga duch kelmoqda Internetda qidiruv, fintech, shahar informatika va biznes informatika. Olimlar cheklovlarga duch kelishmoqda elektron fan ish, shu jumladan meteorologiya, genomika,[5] konnektomika, murakkab fizikani simulyatsiya qilish, biologiya va atrof-muhitni tadqiq qilish.[6]
Ma'lumotlar to'plami ma'lum darajada tez o'sib boradi, chunki ular tobora arzon va ko'p sonli ma'lumotni yig'ish orqali to'planmoqda Internetdagi narsalar kabi qurilmalar mobil qurilmalar, havo (masofadan turib zondlash ), dasturiy ta'minot jurnallari, kameralar, mikrofonlar, radiochastota identifikatsiyasi (RFID) o'quvchilar va simsiz sensorli tarmoqlar.[7][8] Axborotni saqlash bo'yicha dunyoning jon boshiga texnologik quvvati 1980-yillarga qaraganda har 40 oyda qariyb ikki baravarga oshdi;[9] 2012 yildan boshlab[yangilash], har kuni 2.5 ekzabayt (2.5×260 bayt) ma'lumotlar hosil bo'ladi.[10] Asosida IDC hisobotni prognoz qilish, global ma'lumotlar hajmi 4.4 dan shiddat bilan o'sishi taxmin qilingan zettabayt 2013 yildan 2020 yilgacha 44 zettabaytgacha. 2025 yilga kelib, IDC 163 zettabayt ma'lumot bo'lishini taxmin qilmoqda.[11] Yirik korxonalar uchun bitta savol - bu butun tashkilotga ta'sir qiladigan katta ma'lumotlar tashabbuslari kimga tegishli bo'lishi.[12]
Ma'lumotlar bazasini boshqarish tizimlari, ish stoli statistika[tushuntirish kerak ] va ma'lumotlarni tasavvur qilish uchun ishlatiladigan dasturiy ta'minot to'plamlari ko'pincha katta ma'lumotlar bilan ishlashda qiyinchiliklarga duch keladi. Ish uchun "o'nlab, yuzlab va hatto minglab serverlarda ishlaydigan katta miqdordagi parallel dasturiy ta'minot" talab qilinishi mumkin.[13] "Katta ma'lumotlar" deb nomlanadigan narsa foydalanuvchilarning imkoniyatlari va ularning vositalariga qarab o'zgarib turadi va imkoniyatlarning kengayishi katta ma'lumotlarni harakatlanuvchi maqsadga aylantiradi. "Yuzlab tashkilotlarga duch keladigan ba'zi tashkilotlar uchun gigabayt ma'lumotlar birinchi marta ma'lumotlarni boshqarish imkoniyatlarini qayta ko'rib chiqish zarurligini keltirib chiqarishi mumkin. Boshqalar uchun ma'lumotlar hajmi muhim ahamiyatga ega bo'lgunga qadar o'nlab yoki yuzlab terabayt kerak bo'lishi mumkin. "[14]
Ta'rif
Ushbu atama 1990-yillardan beri qo'llanilib kelinmoqda, ba'zilari esa kredit berishdi Jon Mashey atamani ommalashtirish uchun.[15][16]Katta ma'lumotlarga odatda keng qo'llaniladigan dasturiy ta'minot vositalarining imkoniyatlaridan kattaroq hajmdagi ma'lumotlar to'plamlari kiradi qo'lga olish, kurat o'tgan vaqt ichida ma'lumotlarni boshqarish, boshqarish va qayta ishlash.[17] Katta ma'lumotlar falsafasi tuzilmagan, yarim tuzilgan va tuzilgan ma'lumotlarni qamrab oladi, ammo asosiy e'tibor tuzilmaga ega bo'lmagan ma'lumotlarga qaratilgan.[18] Katta hajmdagi "hajm" - bu doimiy ravishda harakatlanadigan maqsad, 2012 yilga kelib[yangilash] bir necha o'n terabaytdan tortib ko'pgacha zettabayt ma'lumotlar.[19]Katta ma'lumotlar uchun yangi texnika va texnologiyalar to'plami kerak integratsiya dan tushunchalarni ochib berish ma'lumotlar to'plamlari xilma-xil, murakkab va masshtabli.[20]
"Varete", "veracity" va boshqa har xil "V" lar ba'zi bir tashkilotlar tomonidan uni tavsiflash uchun qo'shiladi, ba'zi sanoat idoralari tomonidan qayta ko'rib chiqilgan.[21]
2018 yildagi ta'rifda "Katta ma'lumotlar - bu ma'lumotni boshqarish uchun parallel hisoblash vositalari kerak bo'ladi" va "quyidagilarni ta'kidlaymiz:" Bu parallel dasturlash nazariyalari va ba'zi kafolatlar va imkoniyatlarning yo'qotishlari, foydalanilgan kompyuter fanida aniq va aniq belgilangan o'zgarishni anglatadi. tamonidan qilingan Koddning relyatsion modeli."[22]
Kontseptsiyaning o'sib borayotgan etukligi "katta ma'lumotlar" va "o'rtasidagi farqni yanada aniqroq aniqlaydiIsh intellekti ":[23]
- Business Intelligence amaliy matematikadan foydalanadi va tavsiflovchi statistika narsalarni o'lchash, tendentsiyalarni aniqlash va h.k. uchun yuqori ma'lumot zichligi bo'lgan ma'lumotlar bilan.
- Katta ma'lumotlar matematik tahlil, optimallashtirish, induktiv statistika va tushunchalari chiziqli bo'lmagan tizim identifikatsiyasi[24] past ma'lumot zichligi bo'lgan katta ma'lumot to'plamlaridan qonunlar (regressiyalar, chiziqli bo'lmagan munosabatlar va sabab ta'sirlari) ni chiqarish[25] munosabatlar va bog'liqliklarni ochish yoki natijalar va xatti-harakatlarning bashoratlarini bajarish.[24][26][reklama manbai? ]
Xususiyatlari
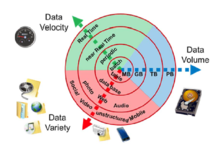
Katta ma'lumotlar quyidagi xususiyatlar bilan tavsiflanishi mumkin:
- Tovush
- Yaratilgan va saqlanadigan ma'lumotlar miqdori. Ma'lumotlarning kattaligi qiymat va potentsial tushunchani va uni katta ma'lumotlar deb hisoblash mumkinmi yoki yo'qligini aniqlaydi. Katta ma'lumotlarning hajmi odatda terabayt va petabaytdan kattaroqdir.[27]
- Turli xillik
- Ma'lumotlarning turi va tabiati. RDBMS kabi oldingi texnologiyalar tuzilgan ma'lumotlarni samarali va samarali ishlashga qodir edi. Shu bilan birga, turi va tabiatining tuzilishdan yarim tuzilishga yoki tuzilmaga o'zgarishi mavjud vositalar va texnologiyalarga qarshi chiqdi. Big Data texnologiyalari yuqori tezlik (tezlik) va katta hajm (hajm) bilan hosil qilingan yarim tuzilgan va tuzilmaviy bo'lmagan (xilma-xil) ma'lumotlarni to'plash, saqlash va qayta ishlashga intilish bilan rivojlandi. Keyinchalik, ushbu vositalar va texnologiyalar o'rganilgan va tuzilgan ma'lumotlar bilan ishlash uchun ishlatilgan, ammo saqlash uchun afzalroqdir. Oxir oqibat, katta hajmdagi ma'lumotlar yoki an'anaviy RDBMSlardan foydalangan holda, tuzilgan ma'lumotlarni qayta ishlash hali ham ixtiyoriy bo'lib qoldi. Bu ijtimoiy tarmoqlar, jurnal fayllari va datchiklar va boshqalar orqali to'plangan ma'lumotlardan maxfiy tushunchalardan samarali foydalanish bo'yicha ma'lumotlarni tahlil qilishga yordam beradi. Katta ma'lumotlar matn, rasm, audio, video materiallardan olinadi; bundan tashqari u etishmayotgan qismlarni to'ldiradi ma'lumotlar birlashishi.
- Tezlik
- Ma'lumotlarni yaratish va qayta ishlash tezligi o'sish va rivojlanish yo'lidagi talab va muammolarni qondirish uchun. Katta ma'lumotlar ko'pincha real vaqtda mavjud. Ga solishtirganda kichik ma'lumotlar, katta ma'lumotlar doimiy ravishda ishlab chiqariladi. Katta ma'lumotlarga bog'liq bo'lgan tezlikning ikki turi - ishlab chiqarish chastotasi va ishlov berish, yozib olish va nashr etish chastotasi.[28]
- Haqiqat
- Bu ma'lumotlar sifati va ma'lumotlar qiymatiga taalluqli katta ma'lumotlar uchun kengaytirilgan ta'rif.[29] The ma'lumotlar sifati olingan ma'lumotlarning aniq tahlilga ta'sir qilishi juda katta farq qilishi mumkin.[30]
Big Data-ning boshqa muhim xususiyatlari:[31]
- To'liq
- Butun tizim bo'ladimi (ya'ni, = barchasi) yozib olinadi yoki yozib olinadi yoki yo'q.

- Nozik va noyob leksik
- Shunga ko'ra, har bir elementning har bir element bo'yicha aniq ma'lumotlarning nisbati to'plangan elementga va agar element va uning xususiyatlari to'g'ri indekslangan yoki aniqlangan bo'lsa.
- Aloqaviy
- Agar to'plangan ma'lumotlar turli xil ma'lumotlar to'plamlarini birlashtirishga yoki meta-tahlil qilishga imkon beradigan umumiy maydonlarni o'z ichiga olsa.
- Kengaytirilgan
- Agar to'plangan ma'lumotlarning har bir elementidagi yangi maydonlarni osongina qo'shish yoki o'zgartirish mumkin bo'lsa.
- Miqyosi
- Agar ma'lumotlar hajmi tez kengayishi mumkin bo'lsa.
- Qiymat
- Ma'lumotlardan olinadigan yordam dasturi.
- O'zgaruvchanlik
- Bu qiymat yoki boshqa xususiyatlar ular yaratilayotgan kontekstga qarab o'zgarib turadigan ma'lumotlarga tegishli.
Arxitektura
Katta ma'lumotlar omborlari turli shakllarda mavjud bo'lib, ko'pincha maxsus ehtiyojga ega bo'lgan korporatsiyalar tomonidan quriladi. Tijorat sotuvchilari tarixan 1990-yillardan boshlab katta ma'lumotlar uchun ma'lumotlar bazasini parallel boshqarish tizimlarini taklif qilishdi. Ko'p yillar davomida WinterCorp ma'lumotlar bazasining eng yirik hisobotini nashr etdi.[32][reklama manbai? ]
Teradata Korporatsiya 1984 yilda parallel qayta ishlashni sotdi DBC 1012 tizim. Teradata tizimlari birinchi bo'lib 1992 yilda 1 terabaytli ma'lumotlarni saqlagan va tahlil qilgan. Qattiq disklarning disklari 1991 yilda 2,5 Gb bo'lgan, shuning uchun katta ma'lumotlarning ta'rifi doimiy ravishda o'zgarib boradi Krayder qonuni. Teradata 2007 yilda birinchi petabaytli RDBMS asosidagi tizimni o'rnatgan. 2017 yil holatiga ko'ra[yangilash], bir necha o'nlab petabaytli Teradata ma'lumotlar bazalari o'rnatilgan, ularning eng kattasi 50 PB dan oshadi. 2008 yilgacha bo'lgan tizimlar 100% tuzilgan relyatsion ma'lumotlar edi. O'shandan beri Teradata tarkibiga kirmagan ma'lumotlar turlarini qo'shdi XML, JSON va Avro.
2000 yilda Seisint Inc. (hozir LexisNexis tavakkalchilik echimlari ) ishlab chiqilgan C ++ ma'lumotlar bazasini qayta ishlash va so'rovlarni o'tkazish uchun asoslangan tarqatilgan platforma HPCC tizimlari platforma. Ushbu tizim bir nechta tovar serverlarida tuzilgan, yarim tuzilgan va tuzilmagan ma'lumotlarni avtomatik ravishda taqsimlaydi, tarqatadi, saqlaydi va etkazib beradi. Foydalanuvchilar ma'lumotlarni qayta ishlash quvurlari va so'rovlarini ECL deb nomlangan ma'lumotlar oqimi dasturlash tilida yozishlari mumkin. ECL-da ishlaydigan ma'lumotlar tahlilchilaridan ma'lumotlar sxemalarini oldindan belgilash talab qilinmaydi va ularning echimini ishlab chiqishda ma'lumotni iloji boricha eng yaxshi shaklda o'zgartirib, mavjud muammoga e'tibor qaratishlari mumkin. 2004 yilda LexisNexis Seisint Inc.[33] va ularning yuqori tezlikda ishlaydigan parallel ishlash platformasi va ushbu platformani Choicepoint Inc.ning 2008 yilda ushbu kompaniyani sotib olganlarida ma'lumotlar tizimlarini birlashtirish uchun muvaffaqiyatli ishlatgan.[34] 2011 yilda HPCC tizimlari platformasi Apache v2.0 litsenziyasi asosida ochiq manbalar bilan ta'minlandi.
CERN va boshqa fizika tajribalari ko'p yillar davomida katta ma'lumotlar to'plamlarini to'plagan, odatda orqali tahlil qilinadi yuqori samarali hisoblash xaritalarni qisqartirish me'morchiligidan ko'ra, odatda, hozirgi "katta ma'lumotlar" harakati nazarda tutilgan.
2004 yilda, Google deb nomlangan jarayon haqida maqola nashr etdi MapReduce shunga o'xshash arxitekturadan foydalanadi. MapReduce kontseptsiyasi parallel ishlov berish modelini taqdim etadi va juda katta hajmdagi ma'lumotlarni qayta ishlash uchun tegishli dastur chiqarildi. MapReduce yordamida so'rovlar bo'linadi va parallel tugunlarga taqsimlanadi va parallel ravishda qayta ishlanadi (Map bosqichi). Keyin natijalar to'planib, etkazib beriladi (qisqartirish bosqichi). Ushbu ramka juda muvaffaqiyatli bo'ldi,[35] shuning uchun boshqalar algoritmni takrorlashni xohlashdi. Shuning uchun, bir amalga oshirish MapReduce ramkasining nomi Apache ochiq manbali loyihasi tomonidan qabul qilingan Hadoop.[36] Apache uchquni MapReduce paradigmasidagi cheklovlarga javoban 2012 yilda ishlab chiqilgan, chunki u ko'plab operatsiyalarni sozlash imkoniyatini qo'shadi (shunchaki xaritani qisqartirish bilan emas).
MIKE2.0 "Katta ma'lumotlar echimini taklif qilish" nomli maqolada aniqlangan katta ma'lumotlarning oqibatlari tufayli qayta ko'rib chiqish zarurligini tan oladigan axborotni boshqarish uchun ochiq yondashuv.[37] Metodika katta ma'lumotlarga foydali nuqtai nazardan murojaat qiladi almashtirishlar ma'lumotlar manbalari, murakkablik o'zaro aloqada va individual yozuvlarni yo'q qilish (yoki o'zgartirish) qiyinligi.[38]
2012 yilgi tadqiqotlar shuni ko'rsatdiki, ko'p qatlamli arxitektura katta ma'lumotlar keltiradigan muammolarni hal qilishning bir variantidir. A parallel taqsimlangan arxitektura ma'lumotlarni bir nechta serverlarga tarqatadi; bu parallel ijro etish muhitlari ma'lumotlarni qayta ishlash tezligini keskin yaxshilashi mumkin. Ushbu turdagi arxitektura MapReduce va Hadoop ramkalaridan foydalanishni amalga oshiradigan parallel ma'lumotlar bazasiga ma'lumotlarni kiritadi. Ushbu turdagi ramka oldingi dastur serveridan foydalanib, ishlov berish quvvatini oxirgi foydalanuvchiga shaffof qiladi.[39]
The ma'lumotlar ko'l axborotni boshqarish o'zgaruvchan dinamikasiga javob berish uchun tashkilotga markazlashtirilgan boshqaruvdan umumiy modelga yo'naltirishga imkon beradi. Bu ma'lumotlar ko'lida ma'lumotlarni tezda ajratishga imkon beradi va shu bilan qo'shimcha vaqtni qisqartiradi.[40][41]
Texnologiyalar
2011 yil McKinsey Global Instituti hisobot katta ma'lumotlarning asosiy tarkibiy qismlari va ekotizimini quyidagicha tavsiflaydi:[42]
- Kabi ma'lumotlarni tahlil qilish usullari A / B sinovlari, mashinada o'rganish va tabiiy tilni qayta ishlash
- Kabi katta ma'lumotlar texnologiyalari biznes razvedkasi, bulutli hisoblash va ma'lumotlar bazalari
- Diagrammalar, grafikalar va boshqa ma'lumotlarni namoyish qilish kabi vizualizatsiya
Ko'p o'lchovli katta ma'lumotlar quyidagicha ifodalanishi mumkin OLAP ma'lumotlar kublari yoki matematik jihatdan, tensorlar. Array ma'lumotlar bazasi tizimlari Ushbu ma'lumotlar turi bo'yicha saqlash va yuqori darajadagi so'rovlarni qo'llab-quvvatlashni ta'minlashga kirishdi, katta ma'lumotlarga qo'llaniladigan qo'shimcha texnologiyalarga tensor asosida samarali hisoblash,[43] kabi ko'p satrli subspace o'rganish.,[44] ommaviy ravishda qayta ishlash (MPP ma'lumotlar bazalari, qidiruvga asoslangan dasturlar, ma'lumotlar qazib olish,[45] tarqatilgan fayl tizimlari, tarqatilgan kesh (masalan, portlash buferi va Yashirilgan ), tarqatilgan ma'lumotlar bazalari, bulut va HPC asosida infratuzilma (ilovalar, saqlash va hisoblash resurslari)[46] va Internet.[iqtibos kerak ] Garchi ko'plab yondashuvlar va texnologiyalar ishlab chiqilgan bo'lsa-da, katta ma'lumotlarga asoslangan holda mashinasozlik mashg'ulotlarini o'tkazish hali ham qiyin bo'lib qolmoqda.[47]
Biroz MPP relyatsion ma'lumotlar bazalari petabaytli ma'lumotlarni saqlash va boshqarish qobiliyatiga ega. Yopiq - bu ma'lumotlarning katta jadvallarini yuklash, kuzatish, zaxira nusxasini yaratish va ulardan foydalanishni optimallashtirish qobiliyatidir RDBMS.[48][reklama manbai? ]
DARPA "s Topologik ma'lumotlarni tahlil qilish Dastur katta hajmdagi ma'lumotlar to'plamining asosiy tuzilishini izlaydi va 2008 yilda ushbu kompaniyaning ishga tushirilishi bilan texnologiya ommalashdi Ayasdi.[49][uchinchi tomon manbai kerak ]
Katta ma'lumotni tahlil qilish jarayonlarining amaliyotchilari, odatda, sekinroq birgalikda saqlashga qarshi,[50] to'g'ridan-to'g'ri biriktirilgan saqlashni afzal ko'rish (DAS ) qattiq holatdagi qo'zg'atuvchidan turli xil shakllarda (SSD ) yuqori quvvatga SATA parallel ishlov berish tugunlari ichiga ko'milgan disk. Birgalikda saqlash arxitekturasini qabul qilish -Saqlash tarmog'i (SAN) va Tarmoqqa biriktirilgan xotira (NAS) - ular nisbatan sekin, murakkab va qimmat. Ushbu fazilatlar tizimning ishlashi, tovar infratuzilmasi va arzon narxlarda rivojlanayotgan katta ma'lumotlar tahlil tizimlariga mos kelmaydi.
Haqiqiy yoki real vaqtga yaqin axborotni etkazib berish katta ma'lumotlar tahlilining tavsiflovchi xususiyatlaridan biridir. Shuning uchun imkoni boricha va har joyda kechikish oldini olinadi. To'g'ridan-to'g'ri biriktirilgan xotira yoki diskdagi ma'lumotlar yaxshi - a-ning boshqa uchida joylashgan xotira yoki diskdagi ma'lumotlar FK SAN ulanish emas. A narxi SAN analitik dasturlar uchun zarur bo'lgan miqyosda boshqa saqlash texnikalariga qaraganda ancha yuqori.
Katta ma'lumotlarni tahlil qilishda birgalikda saqlashning afzalliklari bilan bir qatorda kamchiliklari ham bor, ammo 2011 yilga kelib katta ma'lumotlar tahlillari amaliyotchilari[yangilash] buni yoqtirmadi.[51][reklama manbai? ]
Ilovalar

Katta ma'lumotlar axborot menejmenti mutaxassislariga talabni shunchalik oshirganki Software AG, Oracle korporatsiyasi, IBM, Microsoft, SAP, EMC, HP va Dell ma'lumotlarni boshqarish va tahlil qilishga ixtisoslashgan dasturiy ta'minot firmalariga 15 milliard dollardan ko'proq mablag 'sarfladilar. 2010 yilda ushbu sohaning qiymati 100 milliard dollardan oshdi va yiliga qariyb 10 foizga o'sdi: umuman dasturiy ta'minot biznesidan qariyb ikki baravar tezroq.[4]
Rivojlangan iqtisodiyotlar tobora ko'proq ma'lumot talab qiladigan texnologiyalardan foydalanadilar. Dunyo bo'ylab mobil telefonlarga 4,6 milliard obuna bor va 1 milliarddan 2 milliardgacha odam Internetga kirmoqda.[4] 1990 yildan 2005 yilgacha dunyo miqyosida 1 milliarddan ortiq odam o'rta sinfga kirdi, demak, ko'proq odamlar savodli bo'lib, bu o'z navbatida axborotning o'sishiga olib keldi. Dunyo bo'ylab telekommunikatsiya tarmoqlari orqali ma'lumot almashishning samarali hajmi 281 ga teng edi petabayt 1986 yilda, 471 petabayt 1993 yilda, 2000 yilda 65, 2,2 eksabayt ekzabayt 2007 yilda[9] va prognozlarga ko'ra, 2014 yilga qadar har yili Internet-trafik miqdori 667 eksabaytni tashkil etadi.[4] Bir taxminlarga ko'ra, dunyo miqyosida saqlanadigan ma'lumotlarning uchdan bir qismi alfasayısal matn va harakatsiz rasm ma'lumotlari shaklida,[52] bu katta ma'lumot dasturlarining ko'pchiligi uchun eng foydali formatdir. Bu, shuningdek, hali foydalanilmagan ma'lumotlarning potentsialini ko'rsatadi (ya'ni video va audio kontent shaklida).
Ko'pgina sotuvchilar katta ma'lumotlar uchun javondan tashqari echimlarni taklif qilishsa-da, mutaxassislar kompaniya etarli texnik imkoniyatlarga ega bo'lsa, kompaniyaning muammolarini hal qilish uchun maxsus ishlab chiqilgan ichki echimlarni ishlab chiqishni tavsiya etadilar.[53]
Hukumat
Hukumat jarayonlarida katta ma'lumotlardan foydalanish va qabul qilish xarajatlar, samaradorlik va innovatsiyalar bo'yicha samaradorlikka imkon beradi,[54] ammo kamchiliklarsiz kelmaydi. Ma'lumotlarni tahlil qilish ko'pincha hukumatning bir nechta qismlaridan (markaziy va mahalliy) hamkorlikda ishlashni va kerakli natijaga erishish uchun yangi va innovatsion jarayonlarni yaratishni talab qiladi.
CRVS (fuqarolik holati dalolatnomalari va hayotiy statistik ma'lumotlar ) tug'ilganidan to o'limigacha bo'lgan barcha guvohnomalarni to'playdi. CRVS hukumatlar uchun katta ma'lumot manbai.
Xalqaro taraqqiyot
Rivojlanish uchun axborot-kommunikatsiya texnologiyalaridan samarali foydalanish bo'yicha tadqiqotlar (ICT4D nomi bilan ham tanilgan) katta ma'lumotlar texnologiyasi muhim hissa qo'shishi, shuningdek, o'ziga xos muammolarni keltirib chiqarishi mumkinligini ko'rsatmoqda. Xalqaro taraqqiyot.[55][56] Katta ma'lumotni tahlil qilishdagi yutuqlar sog'liqni saqlash, ish bilan ta'minlash, muhim rivojlanish sohalarida qarorlarni qabul qilishni yaxshilash uchun iqtisodiy jihatdan samarali imkoniyatlarni taklif etadi. iqtisodiy samaradorlik, jinoyatchilik, xavfsizlik va Tabiiy ofat va resurslarni boshqarish.[57][58][59] Bundan tashqari, foydalanuvchi tomonidan yaratilgan ma'lumotlar eshitilmagan ovozni berish uchun yangi imkoniyatlarni taqdim etadi.[60] Ammo rivojlanayotgan mintaqalar uchun yetarli bo'lmagan texnologik infratuzilma va iqtisodiy va inson resurslarining etishmasligi kabi uzoq davom etadigan muammolar mavjud muammolarni maxfiylik, nomukammal metodologiya va o'zaro muvofiqlik masalalari kabi katta ma'lumotlar bilan yanada kuchaytiradi.[57]
Sog'liqni saqlash
Katta ma'lumotlar analitikasi shaxsiylashtirilgan tibbiyot va retsept bo'yicha tahlillar, klinik xavf aralashuvi va prognozli tahlillar, chiqindilarni va parvarishlarning o'zgaruvchanligini kamaytirish, bemorlarning ma'lumotlarini avtomatlashtirilgan tashqi va ichki hisobotlari, standartlashtirilgan tibbiy atamalar va bemorlarning ro'yxatga olishlari va bo'linadigan nuqta echimlari bilan sog'liqni saqlashni yaxshilashga yordam berdi.[61][62][63][64] Yaxshilashning ayrim yo'nalishlari haqiqatan amalga oshirilganidan ko'ra ko'proq intilishdir. Ichida hosil bo'lgan ma'lumotlar darajasi sog'liqni saqlash tizimlari ahamiyatsiz emas. MHealth, eHealth va kiyiladigan texnologiyalarni qo'shilishi bilan ma'lumotlar hajmi o'sishda davom etadi. Bunga quyidagilar kiradi elektron tibbiy yozuv ma'lumotlar, tasvirlash ma'lumotlari, bemor tomonidan yaratilgan ma'lumotlar, sensor ma'lumotlari va ma'lumotlarni qayta ishlash qiyin bo'lgan boshqa shakllar. Ma'lumotlar va axborot sifatiga ko'proq e'tibor qaratish uchun endi bunday muhitga ehtiyoj katta.[65] "Katta ma'lumotlar ko'pincha"iflos ma'lumotlar Ma'lumotlarning noaniqligi ulushi ma'lumotlar hajmining o'sishi bilan ortib boradi. "Odamlarni katta ma'lumotlar miqyosida tekshirishi mumkin emas va sog'liqni saqlash xizmatida aniqlik va ishonchni boshqarish va o'tkazib yuborilgan ma'lumotlarga ishlov berish uchun aqlli vositalarga ehtiyoj juda katta.[66] Sog'liqni saqlash sohasidagi keng qamrovli ma'lumotlar hozirda elektron shaklda bo'lsa-da, katta ma'lumotlar soyaboniga mos keladi, chunki ko'pchilik tuzilmasiz va ulardan foydalanish qiyin.[67] Sog'liqni saqlash sohasida katta ma'lumotlardan foydalanish shaxsiy huquqlar, shaxsiy hayot va shaxsiy hayot uchun xavflardan tortib, axloqiy muammolarni keltirib chiqardi muxtoriyat, shaffoflik va ishonchga.[68]
Sog'liqni saqlash sohasidagi tadqiqotlardagi katta ma'lumotlar kashfiyotchi biotibbiyot tadqiqotlari nuqtai nazaridan juda istiqbollidir, chunki ma'lumotlarga asoslangan tahlillar gipotezaga asoslangan tadqiqotlarga qaraganda tezroq oldinga siljishi mumkin.[69] Keyinchalik, ma'lumotlarni tahlil qilishda kuzatiladigan tendentsiyalar an'anaviy, gipotezaga asoslangan biologik tadqiqotlar va oxir-oqibat klinik tadqiqotlarda sinovdan o'tkazilishi mumkin.
Sog'liqni saqlash sohasida katta ma'lumotlarga tayanadigan tegishli dasturning kichik sohasi kompyuter yordamida tashxis qo'yish tibbiyotda.[70] Shuni eslash kerak, masalan, uchun epilepsiya har kuni 5 dan 10 Gb gacha ma'lumot yaratish odatiy holdir. [71] Xuddi shunday, ko'krakning bitta siqilmagan tasviri tomosintez o'rtacha 450 MB ma'lumotlar. [72]Bu qaerda joylashgan ko'plab misollarning bir nechtasi kompyuter yordamida tashxis qo'yish katta ma'lumotlardan foydalanadi. Shu sababli, katta ma'lumotlar ettita asosiy muammolardan biri sifatida tan olingan kompyuter yordamida tashxis qo'yish ishlashning keyingi darajasiga erishish uchun tizimlarni engib o'tish kerak. [73]
Ta'lim
A McKinsey Global Instituti o'rganish natijasida 1,5 million yuqori ma'lumotli mutaxassislar va menejerlar etishmasligi aniqlandi[42] va bir qator universitetlar[74][yaxshiroq manba kerak ] shu jumladan Tennessi universiteti va Berkli, ushbu talabni qondirish uchun magistrlik dasturlarini yaratdilar. Shaxsiy o'quv lagerlari ham ushbu talabni qondirish uchun dasturlar ishlab chiqdilar, shu qatorda bepul dasturlar Ma'lumotlar inkubatori yoki shunga o'xshash pullik dasturlar Bosh assambleya.[75] Marketingning o'ziga xos sohasida, Wedel va Kannan ta'kidlagan muammolardan biri[76] marketingning bir nechta sub domenlari (masalan, reklama, reklama aktsiyalari, mahsulot ishlab chiqarish, brendlash) mavjud bo'lib, ularning barchasi har xil turdagi ma'lumotlardan foydalanadi. Hammasi bir xil analitik echimlarni qabul qilish maqsadga muvofiq emasligi sababli, biznes maktablari marketing menejerlarini ushbu kichik sohalarda qo'llaniladigan har xil metodlar bo'yicha keng ma'lumotga ega bo'lishlari uchun katta rasm olishlari va tahlilchilar bilan samarali ishlashlari kerak.
OAV
Ommaviy axborot vositalaridan qanday qilib katta ma'lumotlardan foydalanilishini tushunish uchun avvalo, media-jarayon uchun ishlatiladigan mexanizmga ba'zi bir kontekstni kiritish kerak. Nik Kuldri va Jozef Tyoru buni taklif qilishdi amaliyotchilar ommaviy axborot vositalari va reklama sohasida katta ma'lumotlarga, millionlab shaxslar to'g'risida ma'lumotlarning ko'p sonli nuqtalariga murojaat qilinadi. Sanoat gazeta, jurnal yoki teleko'rsatuvlar kabi o'ziga xos media muhitlardan foydalanishning an'anaviy yondashuvidan uzoqlashmoqda va buning o'rniga iste'molchilarga maqbul joylarda maqbul vaqtlarda maqsadli odamlarga etib boradigan texnologiyalarni jalb qilishadi. Pirovard maqsadi iste'molchining fikriga mos keladigan (statistik jihatdan) xabar yoki tarkibni taqdim etish yoki etkazishdir. Masalan, nashriyot muhitida xaridorlarga murojaat qilish uchun xabarlar (reklama) va tarkib (maqolalar) tobora ko'proq moslashtirilmoqda. ma'lumotlar qazib olish tadbirlar.[77]
- Iste'molchilarni maqsadli yo'naltirish (sotuvchilar tomonidan reklama uchun)[78]
- Ma'lumotni olish
- Ma'lumotlar jurnalistikasi: noshirlar va jurnalistlar noyob va innovatsion tushunchalarni taqdim etish uchun katta ma'lumotlar vositalaridan foydalanadilar va infografika.
4-kanal, inglizlar davlat xizmati televizion eshittirish, katta ma'lumotlar sohasida etakchi va ma'lumotlarni tahlil qilish.[79]
Sug'urta
Tibbiy sug'urta provayderlari oziq-ovqat va kabi ijtimoiy "sog'liqning determinantlari" to'g'risidagi ma'lumotlarni yig'moqdalar Televizor iste'moli, mijozlaridagi sog'liq muammolarini aniqlash uchun oilaviy ahvol, kiyim-kechak hajmi va sotib olish odatlari. Ushbu bashoratlar hozirda narxlash uchun ishlatiladimi-yo'qmi munozarali.[80]
Internet narsalar (IOT)
Katta ma'lumotlar va IOT birgalikda ishlaydi. IOT qurilmalaridan olingan ma'lumotlar qurilmaning o'zaro bog'liqligini xaritalashni ta'minlaydi. Bunday xaritalar media sohasi, kompaniyalar va hukumatlar tomonidan o'z auditoriyasini aniqroq yo'naltirish va media samaradorligini oshirish uchun ishlatilgan. IOT sensorli ma'lumotlarni to'plash vositasi sifatida tobora ko'proq qabul qilinmoqda va bu sensorli ma'lumotlar tibbiyotda ishlatilgan,[81] ishlab chiqarish[82] va transport[83] kontekstlar.
Kevin Eshton, ushbu atamani yaratishga loyiq bo'lgan raqamli innovatsiyalar bo'yicha mutaxassis,[84] Ushbu iqtibosda "narsalar Internetini" quyidagicha belgilaydi: "Agar bizda narsalar haqida hamma narsani biladigan kompyuterlar bo'lsa - ular bizdan yordam olmasdan yig'ilgan ma'lumotlardan foydalangan bo'lsalar - biz hamma narsani kuzatib, hisoblab, isrofgarchilik va yo'qotishlarni sezilarli darajada kamaytirgan bo'lar edik. va narx. Nimalarni almashtirish, ta'mirlash yoki esga tushirish kerakligini, yangi yoki eng yaxshi bo'lganligini bilardik. "
Axborot texnologiyalari
Ayniqsa, 2015 yildan beri katta ma'lumotlar taniqli bo'lib qoldi biznes operatsiyalari xodimlarga yanada samarali ishlashga yordam berish va yig'ish va tarqatishni soddalashtirish vositasi sifatida axborot texnologiyalari (IT). Korxonada AT va ma'lumotlarni yig'ish muammolarini hal qilish uchun katta ma'lumotlardan foydalanish deyiladi IT operatsiyalari tahlili (ITOA).[85] Tushunchalariga katta ma'lumotlar tamoyillarini qo'llash orqali mashina razvedkasi va chuqur hisoblash, IT bo'limlari yuzaga kelishi mumkin bo'lgan muammolarni bashorat qilishi va muammolar yuzaga kelguncha echimlarni taklif qilishi mumkin.[85] Bu vaqtda ITOA korxonalari ham katta rol o'ynay boshladilar tizimlarni boshqarish shaxsni olib kelgan platformalarni taklif qilish orqali ma'lumotlar siloslari birgalikda va ma'lumotlarning ajratilgan cho'ntaklaridan emas, balki butun tizimdan tushunchalar hosil qildi.
Keyslar
Hukumat
Xitoy
- Integratsiyalashgan qo'shma operatsiyalar platformasi (IJOP, 一体化 联合 作战 平台) hukumat tomonidan aholini, xususan, kuzatib borish uchun foydalaniladi Uyg'urlar.[86] Biometriya, shu jumladan DNK namunalari, erkin fiziklar dasturi orqali to'planadi.[87]
- 2020 yilga kelib, Xitoy barcha fuqarolariga o'zini tutishiga qarab shaxsiy "Ijtimoiy kredit" balini berishni rejalashtirmoqda.[88] The Ijtimoiy kredit tizimi, hozirda Xitoyning bir qator shaharlarida tajriba sifatida foydalanilmoqda ommaviy kuzatuv bu katta ma'lumotlarni tahlil qilish texnologiyasidan foydalanadi.[89][90]
Hindiston
- Uchun katta ma'lumotlar tahlili sinab ko'rildi BJP Hindiston Umumiy saylovlarida g'alaba qozonish uchun 2014 yil.[91]
- The Hindiston hukumati hind elektoratining hukumat harakatlariga qanday munosabatda bo'lishini aniqlash, shuningdek siyosatni kuchaytirish g'oyalarini aniqlash uchun ko'plab texnikalardan foydalanadi.
Isroil
- Shaxsiy diabet kasalligini davolash GlucoMe-ning katta ma'lumotlar echimi orqali yaratilishi mumkin.[92]
Birlashgan Qirollik
Davlat xizmatlarida katta ma'lumotlardan foydalanish misollari:
- Reçeteli dorilar haqida ma'lumotlar: har bir retseptning kelib chiqishi, joylashuvi va vaqtini bir-biriga bog'lab, tadqiqot bo'limi har qanday dori chiqarilishi va Buyuk Britaniyada keng tarqalgan moslashuv o'rtasidagi kechikishni misol qilib keltirdi. Sog'liqni saqlash va g'amxo'rlikning mukammalligi milliy instituti ko'rsatmalar. Bu shuni ko'rsatadiki, yangi yoki eng zamonaviy dorilar umumiy bemorga filtrlash uchun biroz vaqt talab etadi.[93]
- Ma'lumotlarni birlashtirish: mahalliy hokimiyat aralash ma'lumotlar "g'ildiraklarda ovqatlanish" kabi xavfli guruhlarga tegishli xizmatlar, masalan, yo'llarni qo'zg'atuvchi rotalar haqida. Ma'lumotlarning ulanishi mahalliy hokimiyatga ob-havo bilan bog'liq har qanday kechikishni oldini olishga imkon berdi.[94]
Amerika Qo'shma Shtatlari
- 2012 yilda Obama ma'muriyati hukumat duch keladigan muhim muammolarni hal qilishda qanday katta ma'lumotlardan foydalanish mumkinligini o'rganish uchun Katta Ma'lumotlarni Tadqiqot va Rivojlantirish Tashabbusini e'lon qildi.[95] Ushbu tashabbus oltita bo'limga tarqalgan 84 ta turli xil katta ma'lumotlar dasturlaridan iborat.[96]
- Katta ma'lumotlar tahlili katta rol o'ynadi Barak Obama muvaffaqiyatli 2012 yilgi qayta saylov kampaniyasi.[97]
- The Amerika Qo'shma Shtatlari Federal hukumati eng kuchli o'ntadan beshtasiga egalik qiladi superkompyuterlar dunyoda.[98][99]
- The Yuta ma'lumotlar markazi Amerika Qo'shma Shtatlari tomonidan qurilgan Milliy xavfsizlik agentligi. Tugatgandan so'ng, ushbu muassasa Internet orqali NSA tomonidan to'plangan katta miqdordagi ma'lumot bilan ishlash imkoniyatiga ega bo'ladi. Saqlash joyining aniq miqdori noma'lum, ammo so'nggi manbalar bu bir nechta buyurtma asosida bo'lishini da'vo qilmoqda ekzabayt.[100][101][102] Bu to'plangan ma'lumotlarning maxfiyligi bilan bog'liq xavfsizlik bilan bog'liq muammolarni keltirib chiqardi.[103]
Chakana savdo
- Walmart soatiga 1 milliondan ortiq mijozlar bilan operatsiyalarni amalga oshiradi, ular 2,5 petabayt (2560 terabayt) dan ortiq ma'lumotlarni o'z ichiga olgan ma'lumotlar bazalariga import qilinadi - bu AQShdagi barcha kitoblarda mavjud bo'lgan ma'lumotlarning 167 baravariga teng. Kongress kutubxonasi.[4]
- Windermere ko'chmas mulki yangi uy sotib oluvchilarga kunning turli vaqtlarida ish joyiga va ishdan qaytib kelish vaqtlarini aniqlashda yordam berish uchun 100 millionga yaqin haydovchilarning joylashuvi haqidagi ma'lumotlardan foydalanadi.[104]
- FICO kartani aniqlash tizimi butun dunyo bo'ylab hisoblarni himoya qiladi.[105]
Ilm-fan
- The Katta Hadron kollayderi tajribalar ma'lumotlarning soniyasiga 40 million marta etkazib beradigan 150 millionga yaqin sensorlarini anglatadi. Bir soniyada qariyb 600 million to'qnashuv mavjud. 99.99995% dan ortiq yozuvlarni yozishdan va filtrlashdan so'ng[106] ushbu oqimlardan soniyada 1000 foiz to'qnashuv mavjud.[107][108][109]
- Natijada, faqat sensori oqimi ma'lumotlarining 0,001% dan kamrog'ida ishlash, barcha to'rt LHC tajribalaridan olingan ma'lumotlar oqimi replikatsiya oldidan yillik 25 petabayt miqdorini tashkil etadi (2012 yil holatiga ko'ra)[yangilash]). Replikatsiya qilinganidan keyin bu taxminan 200 petabaytga aylanadi.
- Agar barcha sensor ma'lumotlari LHC-da yozilgan bo'lsa, ma'lumotlar oqimi bilan ishlash juda qiyin bo'ladi. Ma'lumotlar oqimi yiliga 150 million petabaytdan oshadi yoki 500 ga yaqin ekzabayt kuniga, takrorlashdan oldin. Raqamni istiqbolga qo'yish uchun bu 500 ga teng kvintillion (5×1020) kuniga bayt, dunyodagi barcha boshqa manbalardan deyarli 200 baravar ko'p.
- The Kvadrat kilometrlik massiv minglab antennalardan qurilgan radio teleskopdir. U 2024 yilga qadar ishga tushirilishi kutilmoqda. Birgalikda ushbu antennalar 14 ekzabayt to'plashi va kuniga bitta petabayt saqlashi kutilmoqda.[110][111] Bu hozirgi kunga qadar amalga oshirilgan eng ulkan ilmiy loyihalardan biri hisoblanadi.[112]
- Qachon Sloan Digital Sky Survey (SDSS) 2000 yilda astronomik ma'lumotlarni to'plashni boshladi, u dastlabki bir necha hafta ichida astronomiya tarixida to'plangan barcha ma'lumotlarga qaraganda ko'proq to'plandi. Kechasi taxminan 200 Gb tezlikda davom etayotgan SDSS 140 terabaytdan ortiq ma'lumot to'pladi.[4] Qachon Katta Sinoptik Survey Teleskopi, SDSS vorisi, 2020 yilda Internetga kiradi, uning dizaynerlari har besh kunda shu miqdordagi ma'lumotlarni olishini kutmoqdalar.[4]
- Inson genomini dekodlash dastlab ishlov berish 10 yil davom etgan; endi bunga bir kundan kam vaqt ichida erishish mumkin. So'nggi o'n yil ichida DNK sekvensionlari sekvensiya narxini 10 000 ga bo'lishdi, bu prognoz qilingan narxning pasayishidan 100 baravar arzon Mur qonuni.[113]
- The NASA Iqlimni simulyatsiya qilish markazi (NCCS) Discover superkompyuter klasterida 32 petabaytlik iqlim kuzatuvlari va simulyatsiyalarini saqlaydi.[114][115]
- Google-ning DNAStack kasalliklari va boshqa tibbiy nuqsonlarni aniqlash uchun dunyodagi genetik ma'lumotlarning DNK namunalarini to'playdi va tashkil qiladi. Ushbu tezkor va aniq hisob-kitoblar DNK bilan ishlaydigan ko'plab fan va biologiya mutaxassislaridan biri tomonidan sodir bo'lishi mumkin bo'lgan har qanday "ishqalanish nuqtalari" yoki inson xatolarini yo'q qiladi. Google Genomics-ning bir qismi bo'lgan DNAStack, olimlarga bir necha yil davom etadigan ijtimoiy eksperimentlarni bir zumda ko'lamini kengaytirish uchun Google qidiruv serveridagi katta miqdordagi manbalardan foydalanishga imkon beradi.[116][117]
- 23.va "s DNK ma'lumotlar bazasi dunyo bo'ylab 1000000 dan ortiq odamning genetik ma'lumotlarini o'z ichiga oladi.[118] Kompaniya "anonim to'plangan genetik ma'lumotlar" ni boshqa tadqiqotchilar va farmatsevtika kompaniyalariga tadqiqot maqsadida, agar bemorlar o'zlarining roziligini bersa, sotishni o'rganishadi.[119][120][121][122][123] Ahmad Hariri, psixologiya va nevrologiya professori Dyuk universiteti 2009 yildan beri o'z tadqiqotlarida 23andMe dan foydalanib kelayotgan kompaniyaning yangi xizmatining eng muhim jihati shundaki, bu genetik tadqiqotlarni olimlar uchun qulay va nisbatan arzon qilishidir.[119] 23andMe ma'lumotlar bazasida depressiya bilan bog'liq bo'lgan 15 ta genom saytlarini aniqlagan tadqiqot, 23andMe bilan omborga kirishga bo'lgan talablarning ko'payishiga olib keldi, bu nashrdan keyin ikki hafta ichida depressiya ma'lumotlariga kirish uchun 20 ga yaqin so'rov yubordi.[124]
- Suyuqlikning hisoblash dinamikasi (CFD ) va gidrodinamik turbulentlik tadqiqotlar katta ma'lumotlar to'plamlarini yaratadi. Jons Xopkinsning turbulentlik ma'lumotlar bazasi (JHTDB ) tarkibida turli xil turbulent oqimlarning To'g'ridan-to'g'ri raqamli simulyatsiyalaridan 350 terabaytdan ortiq makon-vaqtinchalik maydonlar mavjud. Bunday ma'lumotlarni oddiy simulyatsiya chiqish fayllarini yuklab olish kabi an'anaviy usullardan foydalangan holda bo'lishish qiyin bo'lgan. JHTDB ichidagi ma'lumotlarga to'g'ridan-to'g'ri veb-brauzer so'rovlari, mijozlar platformalarida bajariladigan Matlab, Python, Fortran va C dasturlari, xom ma'lumotlarni yuklab olish xizmatlarini o'chirish kabi turli xil kirish rejimlari bilan "virtual sensorlar" yordamida kirish mumkin. Ma'lumotlar oxir-oqibat ishlatilgan 150 ta ilmiy nashr.
Sport
Katta ma'lumotlardan sport datchiklaridan foydalangan holda mashg'ulotlar va raqobatchilarni tushunishni yaxshilash uchun foydalanish mumkin. Uchrashuvda g'oliblarni katta ma'lumotlar analitikasi yordamida taxmin qilish ham mumkin.[125]Futbolchilarning kelajakdagi faoliyatini ham taxmin qilish mumkin edi. Shunday qilib, futbolchilarning qiymati va maoshi butun mavsum davomida to'plangan ma'lumotlar asosida aniqlanadi.[126]
Formula-1 poygalarida yuzlab datchiklarga ega poyga avtomobillari terabayt ma'lumot hosil qiladi. Ushbu datchiklar shinalar bosimidan yoqilg'ini yoqish samaradorligini oshirish uchun ma'lumotlar nuqtalarini to'playdi.[127]Ma'lumotlarga asoslanib, muhandislar va ma'lumotlar tahlilchilari poyga g'olibi bo'lish uchun tuzatishlar kiritilishi kerakligini hal qilishadi. Bundan tashqari, katta ma'lumotlardan foydalangan holda, poyga jamoalari mavsum davomida to'plangan ma'lumotlardan foydalangan holda simulyatsiyalar asosida poyga tugash vaqtini oldindan taxmin qilishga harakat qilishadi.[128]
Texnologiya
- eBay.com ikkitadan foydalanadi ma'lumotlar omborlari 7.5 da petabayt va 40PB, shuningdek, 40PB Hadoop qidirish, iste'molchilarning tavsiyalari va savdo-sotiq uchun klaster.[129]
- Amazon.com har kuni millionlab orqa operatsiyalarni, shuningdek yarim milliondan ortiq uchinchi tomon sotuvchilarining so'rovlarini ko'rib chiqadi. Amazonning ishlashini ta'minlaydigan asosiy texnologiya Linuxga asoslangan va 2005 yilga kelib[yangilash] ular dunyodagi uchta eng yirik Linux ma'lumotlar bazalariga ega edilar, ularning hajmi 7,8 TB, 18,5 TB va 24,7 TB.[130]
- Facebook foydalanuvchi bazasidan 50 milliard fotosurat bilan ishlaydi.[131] 2017 yil iyun holatiga ko'ra[yangilash], Facebook 2 milliardga etdi oylik faol foydalanuvchilar.[132]
- Google 2012 yil avgust holatiga ko'ra oyiga taxminan 100 milliard qidiruv ishlarini olib borgan[yangilash].[133]
COVID-19
Davomida Covid-19 pandemiyasi, kasallikning ta'sirini minimallashtirish usuli sifatida katta ma'lumotlar to'plandi. Katta ma'lumotlarning muhim dasturlari orasida virus tarqalishini minimallashtirish, holatlarni aniqlash va tibbiy davolanishni rivojlantirish bor edi.[134]
Yuqtirishni minimallashtirish uchun hukumatlar yuqtirgan odamlarni kuzatishda katta ma'lumotlardan foydalanganlar. Dastlabki asrab oluvchilar kiradi Xitoy, Tayvan, Janubiy Koreya va Isroil.[135][136][137]
Tadqiqot faoliyati
Katta ma'lumotlarda shifrlangan qidiruv va klaster shakllanishi 2014 yil mart oyida Amerika muhandislik ta'limi jamiyatida namoyish etildi. Gautam Siwach shug'ullangan Big Data muammolarini hal qilish tomonidan MIT kompyuter fanlari va sun'iy intellekt laboratoriyasi UNH Research Group-dagi doktor Amir Esmailpour klasterlarning shakllanishi va ularning o'zaro bog'liqligi kabi katta ma'lumotlarning asosiy xususiyatlarini o'rganib chiqdi. Ular texnologiya doirasida aniq ta'riflar va real vaqtdagi misollarni taqdim etish orqali katta ma'lumotlarning xavfsizligi va atamani bulut interfeysida shifrlangan shaklda har xil turdagi ma'lumotlarning mavjudligiga yo'naltirishga e'tibor qaratdilar. Bundan tashqari, ular katta ma'lumotlarning xavfsizligini oshirishga olib keladigan shifrlangan matn bo'yicha tezkor qidiruvga o'tish uchun kodlash texnikasini aniqlashga yondashishni taklif qilishdi.[138]
2012 yil mart oyida Oq Uy milliy "Katta ma'lumotlar tashabbusi" ni e'lon qildi, u oltita Federal bo'lim va agentliklardan iborat bo'lib, katta ma'lumot tadqiqot loyihalariga 200 million dollardan ko'proq mablag 'ajratgan.[139]
Ushbu tashabbusga AMPLab-ga 5 yil davomida 10 million dollarlik "Hisoblash sohasidagi ekspeditsiyalar" milliy ilmiy jamg'armasi kiritilgan[140] Berkli shahridagi Kaliforniya universitetida.[141] AMPLab shuningdek mablag 'oldi DARPA va o'ndan ortiq sanoat homiylari va transport vositalarining tirbandligini bashorat qilishdan tortib ko'plab muammolarga qarshi kurashish uchun katta ma'lumotlardan foydalanadilar[142] saraton kasalligiga qarshi kurashish.[143]
The White House Big Data Initiative also included a commitment by the Department of Energy to provide $25 million in funding over 5 years to establish the scalable Data Management, Analysis and Visualization (SDAV) Institute,[144] led by the Energy Department's Lourens Berkli milliy laboratoriyasi. The SDAV Institute aims to bring together the expertise of six national laboratories and seven universities to develop new tools to help scientists manage and visualize data on the Department's supercomputers.
AQSh shtati Massachusets shtati announced the Massachusetts Big Data Initiative in May 2012, which provides funding from the state government and private companies to a variety of research institutions.[145] The Massachusets texnologiya instituti hosts the Intel Science and Technology Center for Big Data in the MIT kompyuter fanlari va sun'iy intellekt laboratoriyasi, combining government, corporate, and institutional funding and research efforts.[146]
The European Commission is funding the 2-year-long Big Data Public Private Forum through their Seventh Framework Program to engage companies, academics and other stakeholders in discussing big data issues. The project aims to define a strategy in terms of research and innovation to guide supporting actions from the European Commission in the successful implementation of the big data economy. Outcomes of this project will be used as input for Ufq 2020, their next ramka dasturi.[147]
The British government announced in March 2014 the founding of the Alan Turing instituti, named after the computer pioneer and code-breaker, which will focus on new ways to collect and analyze large data sets.[148]
Da Vaterloo universiteti Stratford shaharchasi Canadian Open Data Experience (CODE) Inspiration Day, participants demonstrated how using data visualization can increase the understanding and appeal of big data sets and communicate their story to the world.[149]
Computational social sciences – Anyone can use Application Programming Interfaces (APIs) provided by big data holders, such as Google and Twitter, to do research in the social and behavioral sciences.[150] Often these APIs are provided for free.[150] Tobias Preis va boshq. ishlatilgan Google Trends data to demonstrate that Internet users from countries with a higher per capita gross domestic product (GDP) are more likely to search for information about the future than information about the past. The findings suggest there may be a link between online behaviour and real-world economic indicators.[151][152][153] The authors of the study examined Google queries logs made by ratio of the volume of searches for the coming year ('2011') to the volume of searches for the previous year ('2009'), which they call the 'future orientation index '.[154] They compared the future orientation index to the per capita GDP of each country, and found a strong tendency for countries where Google users inquire more about the future to have a higher GDP. The results hint that there may potentially be a relationship between the economic success of a country and the information-seeking behavior of its citizens captured in big data.
Tobias Preis and his colleagues Helen Susannah Moat and H. Evgeniy Stenli introduced a method to identify online precursors for stock market moves, using trading strategies based on search volume data provided by Google Trends.[155] Ularning tahlili Google da e'lon qilingan turli xil moliyaviy ahamiyatga ega bo'lgan 98 shart bo'yicha qidiruv hajmi Ilmiy ma'ruzalar,[156] moliyaviy jihatdan izlash shartlari bo'yicha qidiruv hajmining oshishi moliyaviy bozorlarda katta yo'qotishlarga moyil bo'lishini ko'rsatadi.[157][158][159][160][161][162][163]
Big data sets come with algorithmic challenges that previously did not exist. Hence, there is a need to fundamentally change the processing ways.[164]
The Workshops on Algorithms for Modern Massive Data Sets (MMDS) bring together computer scientists, statisticians, mathematicians, and data analysis practitioners to discuss algorithmic challenges of big data.[165] Regarding big data, one needs to keep in mind that such concepts of magnitude are relative. As it is stated "If the past is of any guidance, then today’s big data most likely will not be considered as such in the near future."[70]
Sampling big data
An important research question that can be asked about big data sets is whether you need to look at the full data to draw certain conclusions about the properties of the data or is a sample good enough. The name big data itself contains a term related to size and this is an important characteristic of big data. Ammo Namuna olish (statistika) enables the selection of right data points from within the larger data set to estimate the characteristics of the whole population. For example, there are about 600 million tweets produced every day. Is it necessary to look at all of them to determine the topics that are discussed during the day? Is it necessary to look at all the tweets to determine the sentiment on each of the topics? In manufacturing different types of sensory data such as acoustics, vibration, pressure, current, voltage and controller data are available at short time intervals. To predict downtime it may not be necessary to look at all the data but a sample may be sufficient. Big Data can be broken down by various data point categories such as demographic, psychographic, behavioral, and transactional data. With large sets of data points, marketers are able to create and use more customized segments of consumers for more strategic targeting.
There has been some work done in Sampling algorithms for big data. A theoretical formulation for sampling Twitter data has been developed.[166]
Tanqid
Critiques of the big data paradigm come in two flavors: those that question the implications of the approach itself, and those that question the way it is currently done.[167] One approach to this criticism is the field of critical data studies.
Critiques of the big data paradigm
"A crucial problem is that we do not know much about the underlying empirical micro-processes that lead to the emergence of the[se] typical network characteristics of Big Data".[17] In their critique, Snijders, Matzat, and Reips point out that often very strong assumptions are made about mathematical properties that may not at all reflect what is really going on at the level of micro-processes. Mark Graham has leveled broad critiques at Kris Anderson 's assertion that big data will spell the end of theory:[168] focusing in particular on the notion that big data must always be contextualized in their social, economic, and political contexts.[169] Even as companies invest eight- and nine-figure sums to derive insight from information streaming in from suppliers and customers, less than 40% of employees have sufficiently mature processes and skills to do so. To overcome this insight deficit, big data, no matter how comprehensive or well analyzed, must be complemented by "big judgment," according to an article in the Harvard Business Review.[170]
Much in the same line, it has been pointed out that the decisions based on the analysis of big data are inevitably "informed by the world as it was in the past, or, at best, as it currently is".[57] Fed by a large number of data on past experiences, algorithms can predict future development if the future is similar to the past.[171] If the system's dynamics of the future change (if it is not a statsionar jarayon ), the past can say little about the future. In order to make predictions in changing environments, it would be necessary to have a thorough understanding of the systems dynamic, which requires theory.[171] As a response to this critique Alemany Oliver and Vayre suggest to use "abductive reasoning as a first step in the research process in order to bring context to consumers' digital traces and make new theories emerge".[172]Additionally, it has been suggested to combine big data approaches with computer simulations, such as agentlarga asoslangan modellar[57] va murakkab tizimlar. Agent-based models are increasingly getting better in predicting the outcome of social complexities of even unknown future scenarios through computer simulations that are based on a collection of mutually interdependent algorithms.[173][174] Finally, the use of multivariate methods that probe for the latent structure of the data, such as omillarni tahlil qilish va klaster tahlili, have proven useful as analytic approaches that go well beyond the bi-variate approaches (cross-tabs) typically employed with smaller data sets.
In health and biology, conventional scientific approaches are based on experimentation. For these approaches, the limiting factor is the relevant data that can confirm or refute the initial hypothesis.[175]A new postulate is accepted now in biosciences: the information provided by the data in huge volumes (omika ) without prior hypothesis is complementary and sometimes necessary to conventional approaches based on experimentation.[176][177] In the massive approaches it is the formulation of a relevant hypothesis to explain the data that is the limiting factor.[178] The search logic is reversed and the limits of induction ("Glory of Science and Philosophy scandal", C. D. keng, 1926) are to be considered.[iqtibos kerak ]
Maxfiylik advocates are concerned about the threat to privacy represented by increasing storage and integration of shaxsan aniqlanadigan ma'lumotlar; expert panels have released various policy recommendations to conform practice to expectations of privacy.[179][180][181] The misuse of Big Data in several cases by media, companies and even the government has allowed for abolition of trust in almost every fundamental institution holding up society.[182]
Nayef Al-Rodhan argues that a new kind of social contract will be needed to protect individual liberties in a context of Big Data and giant corporations that own vast amounts of information. The use of Big Data should be monitored and better regulated at the national and international levels.[183] Barocas and Nissenbaum argue that one way of protecting individual users is by being informed about the types of information being collected, with whom it is shared, under what constrains and for what purposes.[184]
Critiques of the 'V' model
The 'V' model of Big Data is concerting as it centres around computational scalability and lacks in a loss around the perceptibility and understandability of information. This led to the framework of cognitive big data, which characterizes Big Data application according to:[185]
- Data completeness: understanding of the non-obvious from data;
- Data correlation, causation, and predictability: causality as not essential requirement to achieve predictability;
- Explainability and interpretability: humans desire to understand and accept what they understand, where algorithms don't cope with this;
- Level of automated decision making: algorithms that support automated decision making and algorithmic self-learning;
Critiques of novelty
Large data sets have been analyzed by computing machines for well over a century, including the US census analytics performed by IBM 's punch-card machines which computed statistics including means and variances of populations across the whole continent. In more recent decades, science experiments such as CERN have produced data on similar scales to current commercial "big data". However, science experiments have tended to analyze their data using specialized custom-built yuqori samarali hisoblash (super-computing) clusters and grids, rather than clouds of cheap commodity computers as in the current commercial wave, implying a difference in both culture and technology stack.
Critiques of big data execution
Ulf-Dietrich Reips and Uwe Matzat wrote in 2014 that big data had become a "fad" in scientific research.[150] Tadqiqotchi Dana Boyd has raised concerns about the use of big data in science neglecting principles such as choosing a vakillik namunasi by being too concerned about handling the huge amounts of data.[186] This approach may lead to results that have tarafkashlik u yoki bu tarzda.[187] Integration across heterogeneous data resources—some that might be considered big data and others not—presents formidable logistical as well as analytical challenges, but many researchers argue that such integrations are likely to represent the most promising new frontiers in science.[188]In the provocative article "Critical Questions for Big Data",[189] the authors title big data a part of mifologiya: "large data sets offer a higher form of intelligence and knowledge [...], with the aura of truth, objectivity, and accuracy". Users of big data are often "lost in the sheer volume of numbers", and "working with Big Data is still subjective, and what it quantifies does not necessarily have a closer claim on objective truth".[189] Recent developments in BI domain, such as pro-active reporting especially target improvements in usability of big data, through automated filtrlash ning non-useful data and correlations.[190] Big structures are full of spurious correlations[191] either because of non-causal coincidences (law of truly large numbers ), solely nature of big randomness[192] (Ramsey nazariyasi ) or existence of non-included factors so the hope, of early experimenters to make large databases of numbers "speak for themselves" and revolutionize scientific method, is questioned.[193]
Big data analysis is often shallow compared to analysis of smaller data sets.[194] In many big data projects, there is no large data analysis happening, but the challenge is the chiqarib olish, o'zgartirish, yuklash part of data pre-processing.[194]
Big data is a g'alati so'z and a "vague term",[195][196] but at the same time an "obsession"[196] with entrepreneurs, consultants, scientists and the media. Big data showcases such as Google gripp tendentsiyalari failed to deliver good predictions in recent years, overstating the flu outbreaks by a factor of two. Xuddi shunday, Akademiya mukofotlari and election predictions solely based on Twitter were more often off than on target.Big data often poses the same challenges as small data; adding more data does not solve problems of bias, but may emphasize other problems. In particular data sources such as Twitter are not representative of the overall population, and results drawn from such sources may then lead to wrong conclusions. Google tarjima —which is based on big data statistical analysis of text—does a good job at translating web pages. However, results from specialized domains may be dramatically skewed.On the other hand, big data may also introduce new problems, such as the multiple comparisons problem: simultaneously testing a large set of hypotheses is likely to produce many false results that mistakenly appear significant.Ioannidis argued that "most published research findings are false"[197] due to essentially the same effect: when many scientific teams and researchers each perform many experiments (i.e. process a big amount of scientific data; although not with big data technology), the likelihood of a "significant" result being false grows fast – even more so, when only positive results are published.Furthermore, big data analytics results are only as good as the model on which they are predicated. In an example, big data took part in attempting to predict the results of the 2016 U.S. Presidential Election[198] turli darajadagi muvaffaqiyat bilan.
Critiques of big data policing and surveillance
Big Data has been used in policing and surveillance by institutions like huquqni muhofaza qilish va korporatsiyalar.[199] Due to the less visible nature of data-based surveillance as compared to traditional method of policing, objections to big data policing are less likely to arise. According to Sarah Brayne's Big Data Surveillance: The Case of Policing,[200] big data policing can reproduce existing societal inequalities uchta usulda:
- Placing suspected criminals under increased surveillance by using the justification of a mathematical and therefore unbiased algorithm;
- Increasing the scope and number of people that are subject to law enforcement tracking and exacerbating existing racial overrepresentation in the criminal justice system;
- Encouraging members of society to abandon interactions with institutions that would create a digital trace, thus creating obstacles to social inclusion.
If these potential problems are not corrected or regulating, the effects of big data policing continue to shape societal hierarchies. Conscientious usage of big data policing could prevent individual level biases from becoming institutional biases, Brayne also notes.
Ommaviy madaniyatda
Kitoblar
- Pul to'pi is a non-fiction book that explores how the Oakland Athletics used statistical analysis to outperform teams with larger budgets. 2011 yilda a filmni moslashtirish yulduzcha Bred Pitt ozod qilindi.
- 1984 is a dystopian novel by Jorj Oruell. In 1984 the government collects information on citizens and uses the information to maintain an totalitarian rule.
Film
- Yilda Kapitan Amerika: Qishdagi askar H.Y.D.R.A (disguised as S.H.I.E.L.D ) develops helicarriers that use data to determine and eliminate threats over the globe.
- Yilda Qora ritsar, Botmon uses a sonar device that can spy on all of Gotham Siti. The data is gathered from the mobile phones of people within the city.
Shuningdek qarang
- Big data ethics
- Big Data Maturity Model
- Katta xotira
- C ++
- Ma'lumotlarni curation
- Ma'lumotlar aniqlangan saqlash
- Ma'lumotlar liniyasi
- Data philanthropy
- Ma'lumotlar
- Datafication
- Hujjatlarga asoslangan ma'lumotlar bazasi
- Xotirada ishlov berish
- Katta ma'lumot beruvchi kompaniyalar ro'yxati
- Shahar informatikasi
- Very large database
- XLDB
- Ma'lumotlarni tahlil qilish
Adabiyotlar
- ^ Hilbert, Martin; López, Priscila (2011). "Axborotni saqlash, tarqatish va hisoblash bo'yicha dunyoning texnologik salohiyati". Ilm-fan. 332 (6025): 60–65. Bibcode:2011Sci...332...60H. doi:10.1126/science.1200970. PMID 21310967. S2CID 206531385. Olingan 13 aprel 2016.
- ^ Breur, Tom (July 2016). "Statistical Power Analysis and the contemporary "crisis" in social sciences". Journal of Marketing Analytics. 4 (2–3): 61–65. doi:10.1057/s41270-016-0001-3. ISSN 2050-3318.
- ^ boyd, dana; Crawford, Kate (21 September 2011). "Six Provocations for Big Data". Social Science Research Network: A Decade in Internet Time: Symposium on the Dynamics of the Internet and Society. doi:10.2139/ssrn.1926431. S2CID 148610111.
- ^ a b v d e f g "Data, data everywhere". Iqtisodchi. 25 fevral 2010 yil. Olingan 9 dekabr 2012.
- ^ "Community cleverness required". Tabiat. 455 (7209): 1. September 2008. Bibcode:2008Natur.455....1.. doi:10.1038/455001a. PMID 18769385.
- ^ Reichman OJ, Jones MB, Schildhauer MP (February 2011). "Challenges and opportunities of open data in ecology". Ilm-fan. 331 (6018): 703–5. Bibcode:2011 yil ... 331..703R. doi:10.1126 / science.1197962. PMID 21311007. S2CID 22686503.
- ^ Hellerstein, Joe (9 November 2008). "Parallel Programming in the Age of Big Data". Gigaom Blog.
- ^ Segaran, Tobi; Hammerbacher, Jeff (2009). Beautiful Data: The Stories Behind Elegant Data Solutions. O'Reilly Media. p. 257. ISBN 978-0-596-15711-1.
- ^ a b Hilbert M, López P (April 2011). "The world's technological capacity to store, communicate, and compute information" (PDF). Ilm-fan. 332 (6025): 60–5. Bibcode:2011Sci...332...60H. doi:10.1126/science.1200970. PMID 21310967. S2CID 206531385.
- ^ "IBM What is big data? – Bringing big data to the enterprise". ibm.com. Olingan 26 avgust 2013.
- ^ Reinsel, David; Gantz, John; Rydning, John (13 April 2017). "Data Age 2025: The Evolution of Data to Life-Critical" (PDF). seagate.com. Framingham, MA, US: Xalqaro ma'lumotlar korporatsiyasi. Olingan 2 noyabr 2017.
- ^ Oracle and FSN, "Mastering Big Data: CFO Strategies to Transform Insight into Opportunity" Arxivlandi 2013 yil 4-avgust Orqaga qaytish mashinasi, 2012 yil dekabr
- ^ Jacobs, A. (6 July 2009). "The Pathologies of Big Data". ACMQueue.
- ^ Magoulas, Roger; Lorica, Ben (February 2009). "Introduction to Big Data". 2.0 versiyasi. Sebastopol CA: O'Reilly Media (11).
- ^ John R. Mashey (25 April 1998). "Big Data ... and the Next Wave of InfraStress" (PDF). Slides from invited talk. Usenix. Olingan 28 sentyabr 2016.
- ^ Steve Lohr (1 February 2013). "The Origins of 'Big Data': An Etymological Detective Story". The New York Times. Olingan 28 sentyabr 2016.
- ^ a b Snijders, C.; Matzat, U.; Reips, U.-D. (2012). "'Big Data': Big gaps of knowledge in the field of Internet". Xalqaro Internet fanlari jurnali. 7: 1–5.
- ^ Dedić, N.; Stanier, C. (2017). "Towards Differentiating Business Intelligence, Big Data, Data Analytics and Knowledge Discovery". Innovations in Enterprise Information Systems Management and Engineering. Biznes ma'lumotlarini qayta ishlashda ma'ruza matnlari. 285. Berlin; Heidelberg: Springer International Publishing. 114-122 betlar. doi:10.1007/978-3-319-58801-8_10. ISBN 978-3-319-58800-1. ISSN 1865-1356. OCLC 909580101.
- ^ Everts, Sara (2016). "Axborotning haddan tashqari yuklanishi". Distillashlar. Vol. 2 yo'q. 2. pp. 26–33. Olingan 22 mart 2018.
- ^ Ibrohim; Targio Hashem, Abaker; Yaqoob, Ibrar; Badrul Anuar, Nor; Mokhtar, Salimah; Gani, Abdullah; Ullah Khan, Samee (2015). "big data" on cloud computing: Review and open research issues". Axborot tizimlari. 47: 98–115. doi:10.1016/j.is.2014.07.006.
- ^ Grimes, Seth. "Big Data: Avoid 'Wanna V' Confusion". InformationWeek. Olingan 5 yanvar 2016.
- ^ Fox, Charles (25 March 2018). Data Science for Transport. Springer Textbooks in Earth Sciences, Geography and Environment. Springer. ISBN 9783319729527.
- ^ "avec focalisation sur Big Data & Analytique" (PDF). Bigdataparis.com. Olingan 8 oktyabr 2017.
- ^ a b Billings S.A. "Lineer bo'lmagan tizim identifikatsiyasi: vaqt, chastota va makon-vaqtinchalik domenlarda NARMAX usullari". Vili, 2013 yil
- ^ "le Blog ANDSI » DSI Big Data". Andsi.fr. Olingan 8 oktyabr 2017.
- ^ Les Echos (3 April 2013). "Les Echos – Big Data car Low-Density Data ? La faible densité en information comme facteur discriminant – Archives". Lesechos.fr. Olingan 8 oktyabr 2017.
- ^ Sagiroglu, Seref (2013). "Big data: A review". 2013 International Conference on Collaboration Technologies and Systems (CTS): 42–47. doi:10.1109/CTS.2013.6567202. ISBN 978-1-4673-6404-1. S2CID 5724608.
- ^ Kitchin, Rob; McArdle, Gavin (17 February 2016). "What makes Big Data, Big Data? Exploring the ontological characteristics of 26 datasets". Katta ma'lumotlar va jamiyat. 3 (1): 205395171663113. doi:10.1177/2053951716631130.
- ^ Onay, Ceylan; Öztürk, Elif (2018). "A review of credit scoring research in the age of Big Data". Journal of Financial Regulation and Compliance. 26 (3): 382–405. doi:10.1108/JFRC-06-2017-0054.
- ^ Big Data's Fourth V
- ^ Kitchin, Rob; McArdle, Gavin (5 January 2016). "What makes Big Data, Big Data? Exploring the ontological characteristics of 26 datasets". Katta ma'lumotlar va jamiyat. 3 (1): 205395171663113. doi:10.1177/2053951716631130. ISSN 2053-9517.
- ^ "Survey: Biggest Databases Approach 30 Terabytes". Eweek.com. Olingan 8 oktyabr 2017.
- ^ "LexisNexis To Buy Seisint For $775 Million". Washington Post. Olingan 15 iyul 2004.
- ^ https://www.washingtonpost.com/wp-dyn/content/article/2008/02/21/AR2008022100809.html
- ^ Bertolucci, Jeff "Hadoop: From Experiment To Leading Big Data Platform", "Information Week", 2013. Retrieved on 14 November 2013.
- ^ Vebster, Jon. "MapReduce: soddalashtirilgan ma'lumotlarni katta klasterlarda qayta ishlash", "Search Storage", 2004. Retrieved on 25 March 2013.
- ^ "Big Data Solution Offering". MIKE2.0. Olingan 8 dekabr 2013.
- ^ "Big Data Definition". MIKE2.0. Olingan 9 mart 2013.
- ^ Boja, C; Pocovnicu, A; Bătăgan, L. (2012). "Distributed Parallel Architecture for Big Data". Informatica Economica. 16 (2): 116–127.
- ^ "SOLVING KEY BUSINESS CHALLENGES WITH A BIG DATA LAKE" (PDF). Hcltech.com. 2014 yil avgust. Olingan 8 oktyabr 2017.
- ^ "Method for testing the fault tolerance of MapReduce frameworks" (PDF). Computer Networks. 2015 yil.
- ^ a b Manyika, Jeyms; Chuy, Maykl; Bughin, Jaques; Jigarrang, Bred; Dobbs, Richard; Roksburg, Charlz; Byers, Angela Hung (May 2011). "Big Data: The next frontier for innovation, competition, and productivity". McKinsey Global Instituti. Olingan 16 yanvar 2016. Iqtibos jurnali talab qiladi
| jurnal =(Yordam bering) - ^ "Tensorga asoslangan hisoblash va modellashtirishning kelajakdagi yo'nalishlari" (PDF). 2009 yil may.
- ^ Lu, Xaypin; Plataniotis, K.N .; Venetsanopulos, A.N. (2011). "Tensor ma'lumotlarini ko'p satrli pastki fazoni o'rganish bo'yicha so'rov" (PDF). Naqshni aniqlash. 44 (7): 1540–1551. doi:10.1016 / j.patcog.2011.01.004.
- ^ Pllana, Sabri; Janciak, Ivan; Brezany, Peter; Wöhrer, Alexander (2016). "A Survey of the State of the Art in Data Mining and Integration Query Languages". 2011 14th International Conference on Network-Based Information Systems. 2011 International Conference on Network-Based Information Systems (NBIS 2011). IEEE Kompyuter Jamiyati. pp. 341–348. arXiv:1603.01113. Bibcode:2016arXiv160301113P. doi:10.1109/NBiS.2011.58. ISBN 978-1-4577-0789-6. S2CID 9285984.
- ^ Wang, Yandong; Oltin tosh, Robin; Yu, Veykuan; Vang, Teng (2014 yil oktyabr). "HPC tizimlarida xotira-rezident MapReduce-ni tavsiflash va optimallashtirish". 2014 IEEE 28-chi xalqaro parallel va taqsimlangan ishlov berish simpoziumi. IEEE. 799-808 betlar. doi:10.1109 / IPDPS.2014.87. ISBN 978-1-4799-3800-1. S2CID 11157612.
- ^ L'Heureux, A.; Grolinger, K.; Elyamany, H. F.; Capretz, M. A. M. (2017). "Machine Learning With Big Data: Challenges and Approaches". IEEE Access. 5: 7776–7797. doi:10.1109/ACCESS.2017.2696365. ISSN 2169-3536.
- ^ Monash, Curt (30 April 2009). "eBay's two enormous data warehouses".
Monash, Curt (6 October 2010). "eBay followup – Greenplum out, Teradata > 10 petabytes, Hadoop has some value, and more". - ^ "Resources on how Topological Data Analysis is used to analyze big data". Ayasdi.
- ^ CNET News (1 April 2011). "Storage area networks need not apply".
- ^ "How New Analytic Systems will Impact Storage". 2011 yil sentyabr. Arxivlangan asl nusxasi 2012 yil 1 martda.
- ^ Hilbert, Martin (2014). "What is the Content of the World's Technologically Mediated Information and Communication Capacity: How Much Text, Image, Audio, and Video?". Axborot jamiyati. 30 (2): 127–143. doi:10.1080/01972243.2013.873748. S2CID 45759014.
- ^ Rajpurohit, Anmol (11 July 2014). "Interview: Amy Gershkoff, Director of Customer Analytics & Insights, eBay on How to Design Custom In-House BI Tools". KDnuggets. Olingan 14 iyul 2014.
Dr. Amy Gershkoff: "Generally, I find that off-the-shelf business intelligence tools do not meet the needs of clients who want to derive custom insights from their data. Therefore, for medium-to-large organizations with access to strong technical talent, I usually recommend building custom, in-house solutions."
- ^ "The Government and big data: Use, problems and potential". Computerworld. 2012 yil 21 mart. Olingan 12 sentyabr 2016.
- ^ "White Paper: Big Data for Development: Opportunities & Challenges (2012) – United Nations Global Pulse". Unglobalpulse.org. Olingan 13 aprel 2016.
- ^ "WEF (World Economic Forum), & Vital Wave Consulting. (2012). Big Data, Big Impact: New Possibilities for International Development". Jahon iqtisodiy forumi. Olingan 24 avgust 2012.
- ^ a b v d Hilbert, Martin (15 January 2013). "Rivojlanish uchun katta ma'lumotlar: Axborotdan - Bilim jamiyatlariga". SSRN 2205145. Iqtibos jurnali talab qiladi
| jurnal =(Yordam bering) - ^ "Elena Kvochko, Four Ways To talk About Big Data (Information Communication Technologies for Development Series)". worldbank.org. 2012 yil 4-dekabr. Olingan 30 may 2012.
- ^ "Daniele Medri: Big Data & Business: An on-going revolution". Statistics Views. 2013 yil 21 oktyabr.
- ^ Tobias Knobloch and Julia Manske (11 January 2016). "Responsible use of data". D + C, rivojlanish va hamkorlik.
- ^ Huser V, Cimino JJ (July 2016). "Impending Challenges for the Use of Big Data". Xalqaro radiatsion onkologiya, biologiya, fizika jurnali. 95 (3): 890–894. doi:10.1016/j.ijrobp.2015.10.060. PMC 4860172. PMID 26797535.
- ^ Sejdic, Ervin; Falk, Tiago H. (4 July 2018). Signal Processing and Machine Learning for Biomedical Big Data. Sejdić, Ervin, Falk, Tiago H. [Place of publication not identified]. ISBN 9781351061216. OCLC 1044733829.
- ^ Raghupathi W, Raghupathi V (December 2014). "Big data analytics in healthcare: promise and potential". Health Information Science and Systems. 2 (1): 3. doi:10.1186/2047-2501-2-3. PMC 4341817. PMID 25825667.
- ^ Viceconti M, Hunter P, Hose R (July 2015). "Big data, big knowledge: big data for personalized healthcare" (PDF). IEEE biomedikal va sog'liqni saqlash informatika jurnali. 19 (4): 1209–15. doi:10.1109/JBHI.2015.2406883. PMID 26218867. S2CID 14710821.
- ^ O'Donoghue, John; Herbert, Jon (1 oktyabr 2012). "MHealth muhitida ma'lumotlarni boshqarish: bemorlarning sensorlari, mobil qurilmalar va ma'lumotlar bazalari". Ma'lumotlar va axborot sifati jurnali. 4 (1): 5:1–5:20. doi:10.1145/2378016.2378021. S2CID 2318649.
- ^ Mirkes EM, Coats TJ, Levesley J, Gorban AN (August 2016). "Handling missing data in large healthcare dataset: A case study of unknown trauma outcomes". Biologiya va tibbiyotdagi kompyuterlar. 75: 203–16. arXiv:1604.00627. Bibcode:2016arXiv160400627M. doi:10.1016/j.compbiomed.2016.06.004. PMID 27318570. S2CID 5874067.
- ^ Murdoch TB, Detsky AS (April 2013). "The inevitable application of big data to health care". JAMA. 309 (13): 1351–2. doi:10.1001/jama.2013.393. PMID 23549579.
- ^ Vayena E, Salathé M, Madoff LC, Brownstein JS (February 2015). "Ethical challenges of big data in public health". PLOS hisoblash biologiyasi. 11 (2): e1003904. Bibcode:2015PLSCB..11E3904V. doi:10.1371/journal.pcbi.1003904. PMC 4321985. PMID 25664461.
- ^ Copeland, CS (July–August 2017). "Data Driving Discovery" (PDF). Sog'liqni saqlash Nyu-Orlean jurnali: 22–27.
- ^ a b Yanase J, Triantaphyllou E (2019). "A Systematic Survey of Computer-Aided Diagnosis in Medicine: Past and Present Developments". Ilovalar bilan jihozlangan ekspert tizimlari. 138: 112821. doi:10.1016/j.eswa.2019.112821.
- ^ Dong X, Bahroos N, Sadhu E, Jackson T, Chukhman M, Johnson R, Boyd A, Hynes D (2013). "Leverage Hadoop framework for large scale clinical informatics applications". AMIA Joint Summits on Translational Science Proceedings. AMIA Joint Summits on Translational Science. 2013: 53. PMID 24303235.
- ^ Clunie D (2013). "Breast tomosynthesis challenges digital imaging infrastructure". Iqtibos jurnali talab qiladi
| jurnal =(Yordam bering) - ^ Yanase J, Triantaphyllou E (2019). "The Seven Key Challenges for the Future of Computer-Aided Diagnosis in Medicine". Journal of Medical Informatics. 129: 413–422. doi:10.1016/j.ijmedinf.2019.06.017. PMID 31445285.
- ^ "Degrees in Big Data: Fad or Fast Track to Career Success". Forbes. Olingan 21 fevral 2016.
- ^ "NY gets new boot camp for data scientists: It's free but harder to get into than Harvard". Venture Beat. Olingan 21 fevral 2016.
- ^ Wedel, Michel; Kannan, PK (2016). "Marketing Analytics for Data-Rich Environments". Marketing jurnali. 80 (6): 97–121. doi:10.1509/jm.15.0413. S2CID 168410284.
- ^ Couldry, Nick; Turow, Joseph (2014). "Advertising, Big Data, and the Clearance of the Public Realm: Marketers' New Approaches to the Content Subsidy". Xalqaro aloqa jurnali. 8: 1710–1726.
- ^ "Why Digital Advertising Agencies Suck at Acquisition and are in Dire Need of an AI Assisted Upgrade". Ishti.org. 15 aprel 2018 yil. Olingan 15 aprel 2018.
- ^ "Big data and analytics: C4 and Genius Digital". Ibc.org. Olingan 8 oktyabr 2017.
- ^ Marshall Allen (17 July 2018). "Health Insurers Are Vacuuming Up Details About You – And It Could Raise Your Rates". www.propublica.org. Olingan 21 iyul 2018.
- ^ "QuiO Named Innovation Champion of the Accenture HealthTech Innovation Challenge". Businesswire.com. 2017 yil 10-yanvar. Olingan 8 oktyabr 2017.
- ^ "A Software Platform for Operational Technology Innovation" (PDF). Predix.com. Olingan 8 oktyabr 2017.
- ^ Z. Jenipher Wang (March 2017). "Big Data Driven Smart Transportation: the Underlying Story of IoT Transformed Mobility".
- ^ "That Internet Of Things Thing".
- ^ a b Solnik, Ray. "The Time Has Come: Analytics Delivers for IT Operations". Data Center Journal. Olingan 21 iyun 2016.
- ^ Josh Rogin (2 August 2018). "Ethnic cleansing makes a comeback – in China" (Vashington Post). Olingan 4 avgust 2018.
Add to that the unprecedented security and surveillance state in Xinjiang, which includes all-encompassing monitoring based on identity cards, checkpoints, facial recognition and the collection of DNA from millions of individuals. The authorities feed all this data into an artificial-intelligence machine that rates people's loyalty to the Communist Party in order to control every aspect of their lives.
- ^ "China: Big Data Fuels Crackdown in Minority Region: Predictive Policing Program Flags Individuals for Investigations, Detentions". hrw.org. Human Rights Watch tashkiloti. 26 fevral 2018 yil. Olingan 4 avgust 2018.
- ^ "Discipline and Punish: The Birth of China's Social-Credit System". Millat. 23-yanvar, 2019-yil.
- ^ "China's behavior monitoring system bars some from travel, purchasing property". CBS News. 24 aprel 2018 yil.
- ^ "Xitoyning ijtimoiy kredit tizimi to'g'risida murakkab haqiqat". Simli. 21 yanvar 2019 yil.
- ^ "News: Live Mint". Are Indian companies making enough sense of Big Data?. Jonli yalpiz. 23 iyun 2014 yil. Olingan 22 noyabr 2014.
- ^ "Israeli startup uses big data, minimal hardware to treat diabetes". Olingan 28 fevral 2018.
- ^ "Survey on Big Data Using Data Mining" (PDF). International Journal of Engineering Development and Research. 2015 yil. Olingan 14 sentyabr 2016.
- ^ "Recent advances delivered by Mobile Cloud Computing and Internet of Things for Big Data applications: a survey". Xalqaro tarmoq menejmenti jurnali. 2016 yil 11 mart. Olingan 14 sentyabr 2016.
- ^ Kalil, Tom (29 March 2012). "Big Data is a Big Deal". oq uy. Olingan 26 sentyabr 2012.
- ^ Executive Office of the President (March 2012). "Big Data Across the Federal Government" (PDF). Oq uy. Arxivlandi asl nusxasi (PDF) 2016 yil 11-dekabrda. Olingan 26 sentyabr 2012.
- ^ Lampitt, Andrew (14 February 2013). "The real story of how big data analytics helped Obama win". InfoWorld. Olingan 31 may 2014.
- ^ "November 2018 | TOP500 Supercomputer Sites".
- ^ Hoover, J. Nicholas. "Government's 10 Most Powerful Supercomputers". Axborot haftasi. UBM. Olingan 26 sentyabr 2012.
- ^ Bamford, James (15 March 2012). "NSA mamlakatdagi eng katta josuslik markazini qurmoqda (nima deyayotganingizni tomosha qiling)". Simli jurnal. Olingan 18 mart 2013.
- ^ "Groundbreaking Ceremony Held for $1.2 Billion Utah Data Center". National Security Agency Central Security Service. Arxivlandi asl nusxasi 2013 yil 5 sentyabrda. Olingan 18 mart 2013.
- ^ Hill, Kashmir. "Blueprints of NSA's Ridiculously Expensive Data Center in Utah Suggest It Holds Less Info Than Thought". Forbes. Olingan 31 oktyabr 2013.
- ^ Smith, Gerry; Hallman, Ben (12 June 2013). "NSA Spying Controversy Highlights Embrace of Big Data". Huffington Post. Olingan 7 may 2018.
- ^ Wingfield, Nick (12 March 2013). "Predicting Commutes More Accurately for Would-Be Home Buyers – NYTimes.com". Bits.blogs.nytimes.com. Olingan 21 iyul 2013.
- ^ "FICO® Falcon® Fraud Manager". Fico.com. Olingan 21 iyul 2013.
- ^ Alexandru, Dan. "Prof" (PDF). cds.cern.ch. CERN. Olingan 24 mart 2015.
- ^ "LHC Brochure, English version. A presentation of the largest and the most powerful particle accelerator in the world, the Large Hadron Collider (LHC), which started up in 2008. Its role, characteristics, technologies, etc. are explained for the general public". CERN-Brochure-2010-006-Eng. LHC Brochure, English version. CERN. Olingan 20 yanvar 2013.
- ^ "LHC Guide, English version. A collection of facts and figures about the Large Hadron Collider (LHC) in the form of questions and answers". CERN-Brochure-2008-001-Eng. LHC Guide, English version. CERN. Olingan 20 yanvar 2013.
- ^ Brumfiel, Geoff (19 January 2011). "High-energy physics: Down the petabyte highway". Tabiat. 469. 282-83 betlar. Bibcode:2011Natur.469..282B. doi:10.1038/469282a.
- ^ "IBM Research – Zurich" (PDF). Zurich.ibm.com. Olingan 8 oktyabr 2017.
- ^ "Future telescope array drives development of Exabyte processing". Ars Technica. Olingan 15 aprel 2015.
- ^ "Australia's bid for the Square Kilometre Array – an insider's perspective". Suhbat. 2012 yil 1-fevral. Olingan 27 sentyabr 2016.
- ^ "Delort P., OECD ICCP Technology Foresight Forum, 2012" (PDF). Oecd.org. Olingan 8 oktyabr 2017.
- ^ "NASA – NASA Goddard Introduces the NASA Center for Climate Simulation". Nasa.gov. Olingan 13 aprel 2016.
- ^ Webster, Phil. "Supercomputing the Climate: NASA's Big Data Mission". CSC World. Computer Sciences Corporation. Arxivlandi asl nusxasi 2013 yil 4-yanvarda. Olingan 18 yanvar 2013.
- ^ "These six great neuroscience ideas could make the leap from lab to market". Globe and Mail. 2014 yil 20-noyabr. Olingan 1 oktyabr 2016.
- ^ "DNAstack tackles massive, complex DNA datasets with Google Genomics". Google Cloud Platformasi. Olingan 1 oktyabr 2016.
- ^ "23andMe – Ancestry". 23andme.com. Olingan 29 dekabr 2016.
- ^ a b Potenza, Alessandra (13 July 2016). "23andMe wants researchers to use its kits, in a bid to expand its collection of genetic data". The Verge. Olingan 29 dekabr 2016.
- ^ "This Startup Will Sequence Your DNA, So You Can Contribute To Medical Research". Tezkor kompaniya. 2016 yil 23-dekabr. Olingan 29 dekabr 2016.
- ^ Seyf, Charlz. "23andMe Is Terrifying, but Not for the Reasons the FDA Thinks". Ilmiy Amerika. Olingan 29 dekabr 2016.
- ^ Zaleski, Andrew (22 June 2016). "This biotech start-up is betting your genes will yield the next wonder drug". CNBC. Olingan 29 dekabr 2016.
- ^ Regalado, Antonio. "Qanday qilib 23andMe sizning DNKingizni 1 milliard dollarlik giyohvand moddalarni topadigan mashinaga aylantirdi". MIT Technology Review. Olingan 29 dekabr 2016.
- ^ "23andMe hisobotlari Pfizer depressiyasini o'rganish natijasida ma'lumotlar so'rovlarining tezligi | FierceBiotech". fiercebiotech.com. Olingan 29 dekabr 2016.
- ^ Moyoga qoyil qoling. "Ma'lumot olimlari Springbok mag'lubiyatini taxmin qilishmoqda". itweb.co.za. Olingan 12 dekabr 2015.
- ^ Regina Pazvakavambva. "Bashoratli tahlil, katta ma'lumotlar sportni o'zgartiradi". itweb.co.za. Olingan 12 dekabr 2015.
- ^ Deyv Rayan. "Sport: qayerda katta ma'lumotlar sezgir bo'ladi". huffingtonpost.com. Olingan 12 dekabr 2015.
- ^ Frank Bi. "Formula-1 jamoalari ichki qirralarni olish uchun qanday qilib katta ma'lumotlardan foydalanmoqda". Forbes. Olingan 12 dekabr 2015.
- ^ Tay, Liz. "EBay's 90PB ma'lumotlar ombori ichida". IT yangiliklari. Olingan 12 fevral 2016.
- ^ Layton, Yuliya. "Amazon Technology". Money.howstuffworks.com. Olingan 5 mart 2013.
- ^ "Facebook-ni 500 million foydalanuvchiga va undan tashqariga kengaytirish". Facebook.com. Olingan 21 iyul 2013.
- ^ Konstine, Josh (2017 yil 27-iyun). "Hozirda Facebook oylik 2 milliard foydalanuvchiga ega ... va javobgarlik". TechCrunch. Olingan 3 sentyabr 2018.
- ^ "Google hali ham yiliga kamida 1 trillion qidiruvni amalga oshirmoqda". Qidiruv tizimining Land. 2015 yil 16-yanvar. Olingan 15 aprel 2015.
- ^ Xolid, Obid; Javaid, Mohd; Xon, Ibrohim; Vaishya, Raju (2020). "COVID-19 pandemikasida katta ma'lumotlarning muhim qo'llanilishi". Hind orthapedics jurnali. 54 (4): 526–528. doi:10.1007 / s43465-020-00129-z. PMC 7204193. PMID 32382166.
- ^ Manankur, Vinsent (10 mart 2020). "Koronavirus Evropaning shaxsiy hayotga bo'lgan qarorini sinovdan o'tkazmoqda". Politico. Olingan 30 oktyabr 2020.
- ^ Choudri, Amit Roy (2020 yil 27 mart). "Gov Korona davridagi". Gov Insider. Olingan 30 oktyabr 2020.
- ^ Cellan-Jones, Rori (2020 yil 11-fevral). "Xitoy koronavirus" yaqin aloqa detektori "dasturini ishga tushirdi". BBC. Arxivlandi asl nusxasi 2020 yil 28 fevralda. Olingan 30 oktyabr 2020.
- ^ Siwach, Gautam; Esmailpour, Amir (2014 yil mart). Katta ma'lumotlarda shifrlangan qidiruv va klaster shakllanishi (PDF). ASEE 2014 konferentsiyasi. Bridgeport universiteti, Bridgeport, Konnektikut, AQSh. Arxivlandi asl nusxasi (PDF) 2014 yil 9-avgustda. Olingan 26 iyul 2014.
- ^ "Obama ma'muriyati" katta ma'lumotlar "tashabbusini ochib beradi: 200 million dollarlik yangi ilmiy-tadqiqot investitsiyalari to'g'risida e'lon qiladi" (PDF). Oq uy. Arxivlandi asl nusxasi (PDF) 2012 yil 1-noyabrda.
- ^ "Kaliforniya shtatidagi Berkli shahridagi AMPLab". Amplab.cs.berkeley.edu. Olingan 5 mart 2013.
- ^ "NSF katta ma'lumotlarning federal harakatlarini boshqaradi". Milliy Ilmiy Jamg'arma (NSF). 2012 yil 29 mart.
- ^ Timoti Hunter; Teodor Moldova; Matey Zahariya; Jastin Ma; Maykl Franklin; Piter Abbeel; Aleksandr Bayen (2011 yil oktyabr). Bulutdagi mobil mingyillik tizimini masshtablash.
- ^ Devid Patterson (2011 yil 5-dekabr). "Kompyuter olimlari saraton kasalligini davolashda nima yordam berishlari mumkin". The New York Times.
- ^ "Kotib Chu olimlarga DOE superkompyuterlarida ommaviy ma'lumotlar to'plamini tadqiq qilishni yaxshilashga yordam beradigan yangi institutni e'lon qildi". energiya.gov.
- ^ ofis / press-relizlar / 2012/2012530-gubernator-katta-ma'lumotlar-tashabbusni e'lon qildi.html "Gubernator Patrik Massachusets shtatining katta ma'lumotlar bo'yicha dunyoda etakchi mavqeini mustahkamlash bo'yicha yangi tashabbusini e'lon qildi" Tekshiring
| url =qiymati (Yordam bering). Massachusets shtati. - ^ "Katta ma'lumotlar @ CSAIL". Bigdata.csail.mit.edu. 2013 yil 22-fevral. Olingan 5 mart 2013.
- ^ "Katta ma'lumotlar davlat xususiy forumi". cordis.europa.eu. 2012 yil 1 sentyabr. Olingan 16 mart 2020.
- ^ "Katta ma'lumotlarni o'rganish uchun Alan Turing instituti tashkil etiladi". BBC yangiliklari. 19 mart 2014 yil. Olingan 19 mart 2014.
- ^ "Stratford Kampusidagi Vaterloo Universitetidagi ilhom kuni". betakit.com/. Olingan 28 fevral 2014.
- ^ a b v Reys, Ulf-Ditrix; Matzat, Uve (2014). "Big Data xizmatlaridan foydalangan holda" Big Data "qazib olish". Xalqaro Internet fanlari jurnali. 1 (1): 1–8.
- ^ Preis T, Moat HS, Stenli HE, Bishop SR (2012). "Oldinga intilishning afzalliklarini aniqlash". Ilmiy ma'ruzalar. 2: 350. Bibcode:2012 yil NatSR ... 2E.350P. doi:10.1038 / srep00350. PMC 3320057. PMID 22482034.
- ^ Marklar, Pol (2012 yil 5-aprel). "Internetdagi kelajakdagi izlashlar iqtisodiy muvaffaqiyat bilan bog'liq". Yangi olim. Olingan 9 aprel 2012.
- ^ Johnston, Keysi (2012 yil 6 aprel). "Google Trends boy davlatlar mentaliteti haqida ko'rsatmalarni ochib berdi". Ars Technica. Olingan 9 aprel 2012.
- ^ Tobias Preis (2012 yil 24-may). "Qo'shimcha ma'lumotlar: kelajakka yo'nalish indeksini yuklab olish mumkin" (PDF). Olingan 24 may 2012.
- ^ Filipp Bal (2013 yil 26-aprel). "Google qidiruvlarini hisoblash bozor harakatlarini bashorat qilmoqda". Tabiat. Olingan 9 avgust 2013.
- ^ Preis T, Moat HS, Stenli HE (2013). "Google Trends yordamida moliyaviy bozorlardagi savdo-sotiq xatti-harakatlarini miqdoriy aniqlash". Ilmiy ma'ruzalar. 3: 1684. Bibcode:2013 yil NatSR ... 3E1684P. doi:10.1038 / srep01684. PMC 3635219. PMID 23619126.
- ^ Nik Bilton (2013 yil 26 aprel). "Google Search shartlari fond bozori va ish natijalarini bashorat qilishi mumkin". The New York Times. Olingan 9 avgust 2013.
- ^ Kristofer Metyus (2013 yil 26 aprel). "Investitsiya portfelingiz bilan muammo bormi? Google It!". TIME jurnali. Olingan 9 avgust 2013.
- ^ Filipp Balli (2013 yil 26 aprel). "Google qidiruvlarini hisoblash bozor harakatlarini bashorat qilmoqda". Tabiat. Olingan 9 avgust 2013.
- ^ Bernxard Uorner (2013 yil 25 aprel). "'Katta ma'lumotlar tadqiqotchilari Google-ga bozorlarni engish uchun murojaat qilishdi ". Bloomberg Businessweek. Olingan 9 avgust 2013.
- ^ Xemish Makrey (2013 yil 28 aprel). "Xemish Makrey: Sarmoyadorlar fikri bo'yicha qimmatli maslahat kerakmi? Google it". Mustaqil. London. Olingan 9 avgust 2013.
- ^ Richard Uoters (2013 yil 25 aprel). "Google qidiruvi fond bozorini bashorat qilishda yangi so'z ekanligini isbotlamoqda". Financial Times. Olingan 9 avgust 2013.
- ^ Jeyson Palmer (2013 yil 25-aprel). "Google qidiruvlari bozor harakatlarini bashorat qilmoqda". BBC. Olingan 9 avgust 2013.
- ^ E. Seydić, "Hozirgi vositalarni katta ma'lumotlar bilan ishlashga moslashtirish" Tabiat, jild 507, yo'q. 7492, 306-bet, 2014 yil mart.
- ^ Stenford."MMDS. Zamonaviy massivli ma'lumotlar to'plamining algoritmlari bo'yicha seminar".
- ^ Deepan Palguna; Vikas Joshi; Venkatesan Chakravarti; Ravi Kotari va L. V. Subramaniam (2015). Twitter uchun namuna olish algoritmlarini tahlil qilish. Sun'iy intellekt bo'yicha xalqaro qo'shma konferentsiya.
- ^ Kimble, C .; Milolidakis, G. (2015). "Katta ma'lumotlar va biznes intellekti: afsonalarni buzish". Global biznes va tashkiliy mukammallik. 35 (1): 23–34. arXiv:1511.03085. Bibcode:2015arXiv151103085K. doi:10.1002 / joe.21642. S2CID 21113389.
- ^ Kris Anderson (2008 yil 23-iyun). "Nazariya oxiri: ma'lumotlar toshqini ilmiy uslubni eskiradi". Simli.
- ^ Grem M. (9 mart 2012). "Katta ma'lumotlar va nazariyaning oxiri?". Guardian. London.
- ^ Shoh, Shvetank; Xorn, Endryu; Kapella, Xayme (2012 yil aprel). "Yaxshi ma'lumotlar yaxshi qarorlarni kafolatlamaydi. Garvard biznes sharhi". HBR.org. Olingan 8 sentyabr 2012.
- ^ a b Katta ma'lumotlar uchun katta o'zgarishlarni ko'rish kerak., Hilbert, M. (2014). London: TEDx UCL, x = mustaqil ravishda tashkil etilgan TED muzokaralari
- ^ Alemaniya Oliver, Matyo; Vayre, Jan-Sebastien (2015). "Marketing tadqiqotlarida katta ma'lumotlar va bilimlarni ishlab chiqarish kelajagi: axloq qoidalari, raqamli izlar va o'g'irlab ketuvchi fikrlash". Marketing tahlillari jurnali. 3 (1): 5–13. doi:10.1057 / jma.2015.1. S2CID 111360835.
- ^ Jonathan Rauch (2002 yil 1 aprel). "Burchaklarni ko'rish". Atlantika.
- ^ Epstein, J. M., & Axtell, R. L. (1996). O'sib borayotgan sun'iy jamiyatlar: pastdan yuqoriga ijtimoiy fan. Bredford kitobi.
- ^ "Delort P., Bioscience-dagi katta ma'lumotlar, Big Data Paris, 2012" (PDF). Bigdataparis.com. Olingan 8 oktyabr 2017.
- ^ "Keyingi avlod genomikasi: integral usul" (PDF). tabiat. 2010 yil iyul. Olingan 18 oktyabr 2016.
- ^ "BIOSCIENCES'DAGI KATTA MA'LUMOTLAR". 2015 yil oktyabr. Olingan 18 oktyabr 2016.
- ^ "Katta ma'lumotlar: biz katta xato qilyapmizmi?". Financial Times. 2014 yil 28 mart. Olingan 20 oktyabr 2016.
- ^ Ohm, Pol (2012 yil 23-avgust). "Xarobalar uchun ma'lumotlar bazasini yaratmang". Garvard biznes sharhi.
- ^ Darvin Bond-Grem, Iron Cagebook - Facebook patentlarining mantiqiy oxiri, Counterpunch.org, 2013.12.03
- ^ Darvin Bond-Grem, Tech industriyasining startap konferentsiyasi ichida, Counterpunch.org, 2013.09.11
- ^ Darvin Bond-Grem, Katta ma'lumotlarning istiqboli, ThePerspective.com, 2018
- ^ Al-Rodhan, Nayef (16 sentyabr 2014). "Ijtimoiy shartnoma 2.0: katta ma'lumotlar va shaxsiy hayot va fuqarolik erkinliklarini kafolatlash zarurati - Garvard xalqaro sharhi". Garvard xalqaro sharhi. Arxivlandi asl nusxasi 2017 yil 13 aprelda. Olingan 3 aprel 2017.
- ^ Barokas, Solon; Nissenbaum, Xelen; Leyn, Yuliya; Stodden, Viktoriya; Bender, Stefan; Nissenbaum, Xelen (2014 yil iyun). Big Data-ning anonimlik va rozilik atrofida ishlashi. Kembrij universiteti matbuoti. 44-75 betlar. doi:10.1017 / cbo9781107590205.004. ISBN 9781107067356. S2CID 152939392.
- ^ Lugmayr, Artur; Stokleben, Byorn; Shayb, Kristof; Mailaparampil, Metyu; Mesiya, Noora; Ranta, Xannu; Laboratoriya, Emmi (2016 yil 1-iyun). "KATTA MA'LUMOTLARNI TADQIQOTI VA QO'ShIMChA QO'ShIMChA QO'ShIMChA TADQIQOT - BUYUK MA'LUMOTDA HAQIQATDA" YANGI "NIMA? - BU MUVOFIYAT BUYUK MA'LUMOTLAR!". Iqtibos jurnali talab qiladi
| jurnal =(Yordam bering) - ^ danah boyd (2010 yil 29 aprel). "Katta ma'lumotlar kontekstida maxfiylik va oshkoralik". WWW 2010 konferentsiyasi. Olingan 18 aprel 2011.
- ^ Katyal, Sonia K. (2019). "Sun'iy aql, reklama va dezinformatsiya". Reklama va jamiyat har chorakda. 20 (4). doi:10.1353 / asr.2019.0026. ISSN 2475-1790.
- ^ Jons, MB; Shildhauer, deputat; Reyxman, OJ; Bowers, S (2006). "Yangi bioinformatika: ekologik ma'lumotlarni gendan biosferaga birlashtirish" (PDF). Ekologiya, evolyutsiya va sistematikaning yillik sharhi. 37 (1): 519–544. doi:10.1146 / annurev.ecolsys.37.091305.110031.
- ^ a b Boyd, D.; Krouford, K. (2012). "Katta ma'lumotlar uchun muhim savollar". Axborot, aloqa va jamiyat. 15 (5): 662–679. doi:10.1080 / 1369118X.2012.678878. S2CID 51843165.
- ^ Ishga tushirilmasligi: Katta ma'lumotlardan katta qarorlarga Arxivlandi 2016 yil 6-dekabr kuni Orqaga qaytish mashinasi, Forte Wares.
- ^ "Bir-biri bilan bog'liq bo'lgan 15 ta aqldan ozgan narsa".
- ^ Tasodifiy tuzilmalar va algoritmlar
- ^ Cristian S. Calude, Juzeppe Longo, (2016), Katta ma'lumotdagi soxta korrelyatsiyalar to'foni, Fan asoslari
- ^ a b Gregori Piatetskiy (2014 yil 12-avgust). "Suhbat: Maykl Bertold, KNIME asoschisi, tadqiqot, ijodkorlik, katta ma'lumotlar va shaxsiy hayot to'g'risida, 2-qism".. KDnuggets. Olingan 13 avgust 2014.
- ^ Pelt, Meyson (2015 yil 26-oktabr). ""Big Data "bu ortiqcha ishlatilgan so'zdir va bu Twitter boti buni tasdiqlaydi". siliconangle.com. SiliconANGLE. Olingan 4 noyabr 2015.
- ^ a b Harford, Tim (2014 yil 28 mart). "Katta ma'lumotlar: biz katta xato qilyapmizmi?". Financial Times. Olingan 7 aprel 2014.
- ^ Ioannidis JP (2005 yil avgust). "Nega aksariyat nashr etilgan tadqiqot natijalari yolg'on". PLOS tibbiyoti. 2 (8): e124. doi:10.1371 / journal.pmed.0020124. PMC 1182327. PMID 16060722.
- ^ Lor, Stiv; Xonanda, Natasha (2016 yil 10-noyabr). "Saylovni tayinlashda qanday qilib ma'lumotlarimiz muvaffaqiyatsiz bo'ldi". The New York Times. ISSN 0362-4331. Olingan 27 noyabr 2016.
- ^ "Ma'lumotlarga asoslangan politsiya inson erkinligiga qanday tahdid soladi". Iqtisodchi. 4 iyun 2018 yil. ISSN 0013-0613. Olingan 27 oktyabr 2019.
- ^ Brayne, Sara (2017 yil 29-avgust). "Katta ma'lumotlarga oid kuzatuv: Politsiya ishi". Amerika sotsiologik sharhi. 82 (5): 977–1008. doi:10.1177/0003122417725865. S2CID 3609838.
Qo'shimcha o'qish
| Kutubxona resurslari haqida Katta ma'lumotlar |
- Piter Kinnaird; Inbal Talgam-Koen, nashr. (2012). "Katta ma'lumotlar". ACM Crossroads talabalar jurnali. XRDS: chorrahalar, talabalar uchun ACM jurnali. Vol. 19 yo'q. 1. Hisoblash texnikasi assotsiatsiyasi. ISSN 1528-4980. OCLC 779657714.
- Yure Leskovec; Anand Rajaraman; Jeffri D. Ullman (2014). Katta hajmdagi ma'lumotlar to'plamini qazib olish. Kembrij universiteti matbuoti. ISBN 9781107077232. OCLC 888463433.
- Viktor Mayer-Shonberger; Kennet Kukier (2013). Katta ma'lumotlar: bizning hayotimiz, ishlashimiz va fikrlash tarzimizni o'zgartiradigan inqilob. Houghton Mifflin Harcourt. ISBN 9781299903029. OCLC 828620988.
- Press, Gil (2013 yil 9-may). "Katta ma'lumotlarning juda qisqa tarixi". forbes.com. Jersi Siti, NJ: Forbes jurnali. Olingan 17 sentyabr 2016.
- "Katta ma'lumotlar: boshqaruv inqilobi". hbr.org. Garvard biznes sharhi. 2012 yil oktyabr.
- O'Nil, Keti (2017). Matematikani yo'q qilish qurollari: qanday qilib katta ma'lumotlar tengsizlikni oshiradi va demokratiyaga tahdid soladi. Broadway kitoblari. ISBN 978-0553418835.
Tashqi havolalar
 Bilan bog'liq ommaviy axborot vositalari Katta ma'lumotlar Vikimedia Commons-da
Bilan bog'liq ommaviy axborot vositalari Katta ma'lumotlar Vikimedia Commons-da Ning lug'at ta'rifi katta ma'lumotlar Vikilug'atda
Ning lug'at ta'rifi katta ma'lumotlar Vikilug'atda